Как смотреть удаленные страницы вконтакте. Как посмотреть информацию о пользователе вконтакте, если он удалил страницу
На главной странице архива, есть блок «Wayback Machine» . Здесь вам нужно ввести адрес удаленной страницы, и нажать Enter .

Обратите внимание на интерфейс. В верхней части экрана есть календарь. На нем отображены имеющиеся копии страницы. Если их несколько, вы сможете просмотреть каждую из них. Давайте попробуем отдалиться на 2012 года, и посмотреть, что было на моей странице в то время. На календаре выбираем нужную дату, и получаем вот такой результат.

Если удаленной страницы нет в архиве, вы получите вот такое сообщение.

Просмотр копии профиля в поисковиках
Яндекс и гугл добавляют в свою базу информацию обо всех найденных страницах в сети. Это касается также и аккаунтов в ВК. Версия копии изменяется с каждым обновлением базы (разумеется, при наличии изменений). Этот процесс занимает несколько дней.
Если пользователь совсем недавно, есть шанс, что в поисковых системах еще есть ее сохраненная копия. И мы можем просмотреть ее.
Давайте посмотрим, как это выглядит в яндексе.
Чтобы принцип работы стал более понятен, рассмотрим копию, которая гарантирована существует.
Заходим в яндекс, и набираем в поиске адрес своего аккаунта.

Тот же принцип и в гугл.

Теперь давайте попробуем просмотреть сохраненную копию. Для этого разверните дополнительное меню (кнопка в виде треугольника, расположена рядом с адресом). Здесь нажмите «Сохраненная копия» .


Теперь попробуйте проделать те же действия, для удаленной страницы, которую вы хотите увидеть.
Просмотр кэша браузера
Каждый раз, когда вы открываете страницу сайта, ваш браузер сохраняет ее копию к себе в историю. Это делается для того, чтобы при повторном открытии, не загружать ее заново через интернет, а моментально предоставить вам готовую копию. Это существенно увеличивает скорость работы.
В том случае, если вы совсем недавно заходили к пользователю на страницу, есть вероятность того, что она есть в кэше браузера, и вы можете просмотреть ее.
Давайте сделаем это на примере Mozilla Firefox.
Включите автономный режим. Для этого откройте меню, затем пункт «Разработка» , и далее поставьте галочку «Работать автономно» .

Теперь в адресной строке браузера, вам нужно указать урл нужной страницы, и нажать «Enter» . Если ее копия существует — она будет загружена. Если нет, вы увидите сообщение об ошибке.

Я сделал обзор всех трех способов в видеоформате.
Заключение
Есть вероятность того, что не один из описанных методов, не даст результата, и вам не удастся увидеть информацию с удаленной страницы. В таком случае останется только надеяться на то, что пользователь решит восстановить свой профиль.
Интернет - вещь абсолютно не постоянная. Любой сайт в силу различных обстоятельств (обрывы линий электропередач, банкротство хостера, неоплата домена) может перестать работать. В браузерах пользователей после этого отобразятся только сообщения о недоступности любимого ресурса. Если же сайт изменится до неузнаваемости, а страницу с важной информацией удалит администрация, ресурс продолжит свою работу, но конечному потребителю неприятностей в этом случае не избежать.
Не стоит волноваться и проклинать злой рок. Быть может, портал недоступен временно, а специалисты заняты восстановлением его работы. Помимо этого, у каждого пользователя Глобальной сети есть мощный инструмент, который позволит получить необходимую информацию, - кэш сайтов.
Google - мегакорпорация, мощности серверов которой имеют возможность постоянно сканировать Интернет на предмет появления новых страниц и изменения старых. Добавляя ресурсы в свою базу, алгоритмы не только но и делают их снимки. Грубо говоря, Google создает резервные копии Интернета на тот случай, если исходный материал станет недоступным.
Кэш сайтов Google доступен всем без исключения. Чтобы получить доступ к любой проиндексированной странице, в строку поисковика требуется ввести запрос: . На экране отобразится копия страницы, в верхней части экрана будет показана следующая информация:
- Дата последнего сохранения, что даст возможность судить, могла ли измениться представленная информация.
- Здесь же располагается ссылка на снимок, в котором содержится только текст.
- Еще один URL покажет полный исходный код, который заинтересует веб-мастеров.
Владельцам ресурсов в Интернете нужно знать, что кэш сайтов компании Google - добровольная в использовании система. Если необходимо исключить какие-либо страницы вашего портала из списка сохраненных, можно запретить делать снимки. Для этого на страницу нужно добавить метатег . Также запретить или разрешить кэширование можно в рабочем кабинете, если вы имеете соответствующий аккаунт.
Если же вам нужно удалить уже сохраненные снимки из кэша Google, потребуется отправить электронное письмо с запросом, а потом подтвердить свои права на сайт.
"Яндекс"
На втором месте в списке компаний, сохраняющих кэш сайтов, располагается отечественный гигант индустрии. Охват "Яндекса" намного меньше, поэтому здесь стоит искать в основном снимки крупных, обладающих высокой посещаемостью ресурсов.
Просто введите в поисковую строку URL нужной страницы и нажмите ENTER. Результаты поиска покажут необходимый вам сайт на первом месте выдачи. Рядом со ссылкой на него будет располагаться иконка в виде треугольника. Кликнув на нее и выбрав пункт меню «сохраненная копия», откроете последний доступный снимок страницы.
The Wayback Machine
В 1996 году Брюстер Кейл открыл некоммерческую организацию, которую сейчас называют архивом Интернета. Компания занимается сбором копий веб-страниц, видеоматериалов, графических изображений, аудиозаписей, программного обспечения. Собранный материал архивируется, а бесплатный доступ к нему может получить любой желающий.
Главная цель The Wayback Machine - сохранение культурных ценностей, созданных цивилизацией после широкого распространения Интернета, создание наиболее полной электронной библиотеки человечества. В настоящий момент в Архиве хранится более 10 петабайт данных, что позволяет пользователям ознакомиться с 85 миллиардами веб-страниц. Это значит, Архив - наиболее полный кэш сайтов.

Archive.org - сайт организации, на нем можно попытаться найти снимок необходимой страницы. Так как сохраняется не только последняя копия, а бот просматривает ресурсы периодически, можно изучить все изменения, сделанные на определенной странице с течением времени, даже если сайт уже не существует. В строке поиска желательно использовать префикс WWW.
Dead URL

«Мертвый адрес» предоставляет для пользователей похожие возможности. Скопируйте из нерабочий URL и вставьте его в поле ввода на сайте. Сервис немного подумает и выдаст несколько результатов. Некоторые из них будут ссылаться на ресурс компании Google. Другая часть приведет пользователя на страницы Архива. Что немаловажно, сортируется кэш сайтов по дате, а это очень удобно.
Down Or Not
Если вам необходим кэш сайтов в Интернете в связи с недоступностью того или иного ресурса, но поиски ни к чему не приводят, стоит проверить, не рядом ли с вами проблема. Например, провайдер Интернета выполняет технические работы или заменяет устаревшее оборудование. Для проверки, кто виноват, есть смысл воспользоваться сервисом Down Or Not (Жив или нет).

Введите адрес необходимого вам портала в строку поиска и нажмите на кнопку ENTER. После недолгого анализа сервис выдаст результат. Слово DOWN указывает на недоступность ресурса (временную или постоянную), если же на экране появится слово UP - значит, с порталом всё в порядке.
Down Ot Not выступает в роли стороннего и непредвзятого эксперта, чтобы определить, что именно является источником проблемы.
Иногда, зайдя на (ранее существовавшую) страницу, мы получаем 404 ошибку — страница не найдена. Эта страница удалена, сайт не доступен и т. д., но как просмотреть удалённую страницу ? Попробую дать ответ на этот вопрос и предложить четыре готовых варианта решения этой задачи.
Вариант 1: автономный режим браузера
Для экономии трафика и увеличения скорости загрузки страниц, браузеры используют кэш. Что такое кэш? Кэш (от англ. cache ) — дисковое пространство на компьютере, выделенное под временное хранение файлов, к которым относятся и веб-страницы.
Так что попробуйте просмотреть удаленную страницу из кэша браузера. Для этого — перейдите в автономный режим .
Примечание : просмотр страниц в автономном режиме возможен, только если пользователь посещал страницу ранее и она ещё не удалена из кэша.
Как включить автономный режим работы браузера?
Для Google Chrome , Яндекс.Браузер и др., автономный режим доступен только как эксперимент. Включите его на странице: chrome://flags/ — найдите там «Автономный режим кеша» и кликните ссылку «Включить ».
 Включение и выключение автономного режима в браузере Google Chrome
Включение и выключение автономного режима в браузере Google Chrome
В Firefox (29 и старше) откройте меню (кнопка с тремя полосками) и кликнуть пункт «Разработка » (гаечный ключ) , а потом пункт «Работать автономно ».
 Включение и выключение автономного режима в браузере Firefox
Включение и выключение автономного режима в браузере Firefox
В Opera кликните кнопку «Opera», найдите в меню пункт «Настройки », а потом кликните пункт «Работать автономно ».
 Как включить или отключить автономный режим в Opera?
Как включить или отключить автономный режим в Opera?
В Internet Explorer — нажмите кнопку Alt , (в появившемся меню) выберите пункт «Файл » и кликните пункт меню «Автономный режим ».

Как отключить автономный режим в Internet Explorer 11?
Уточню — в IE 11 разработчики удалили переключение автономного режима. Возникает вопрос — как отключить автономный режим в Internet Explorer 11? Выполнить обратные действия — не получится, сбросьте настройку браузера.
Для этого закройте запущенные приложения, в том числе и браузер. Нажмите комбинацию клавиш Win +R и (в открывшемся окне «Выполнить») введите: inetcpl.cpl , нажмите кнопку Enter . В открывшемся окне «Свойства: Интернет» перейдите на вкладку «Дополнительно ». На открывшейся вкладке найдите и кликните кнопку «Восстановить дополнительные параметры », а потом и появившуюся кнопку «Сброс… ». В окне подтверждения установите галочку «Удалить личные настройки » и нажмите кнопку «Сброс ».
Вариант 2: копии страниц в поисковиках
Ранее я рассказывал , что пользователям поисковиков ненужно заходить на сайты — достаточно посмотреть копию страницы в поисковике, и это хороший способ решения нашей задачи.
В Google — используйте оператор info: , с указанием нужного URL-адреса. Пример:

В Яндекс — используйте оператор url: , с указанием нужного URL-адреса. Пример:

Наведите курсор мыши на (зелёный) URL-адрес в сниппете и кликните появившуюся ссылку «копия ».
Проблема в том, что поисковики хранят только последнюю проиндексированную копию страницы. Если страница удалена, со временем, она станет недоступна и в поисковиках.
Вариант 3: WayBack Machine
Сервис WayBack Machine — Интернет архив, который содержит историю существования сайтов.
 Просмотр истории сайта на WayBack Machine
Просмотр истории сайта на WayBack Machine
Введите нужный URL-адрес, а сервис попытается найти копию указанной страницы в своей базе с привязкой к дате. Но сервис индексирует далеко не все страницы и сайты.
Вариант 4: Archive.today
Простым и (к сожалению) пассивным сервис для создания копий веб-страниц является Archive.today . Получить доступ к удалённой странице можно, если она была скопирована другим пользователем в архив сервис. Для этого введите URL-адрес в первую (красную) форму и нажать кнопку «submit url ».

После этого, попробуйте найти страницу, используя вторую (синюю) форму.

Рекомендую! Подумал: А что делать, если страница не удалена? Бывает же так, что просто невозможно зайти на сайт. Нашел статью Виктора Томилина , которая так и называется «Не могу зайти на сайт » — где автор не просто описывает 4 способа решения проблемы, но и записал наглядное видео.
| в 22:40 | Изменить сообщение | 12 комментариев |
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:http://www.сайт/
Где http://www.сайт/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

6. Archive.is, для собственного кэша

Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса..
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com , перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari .
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:

После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:

Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com :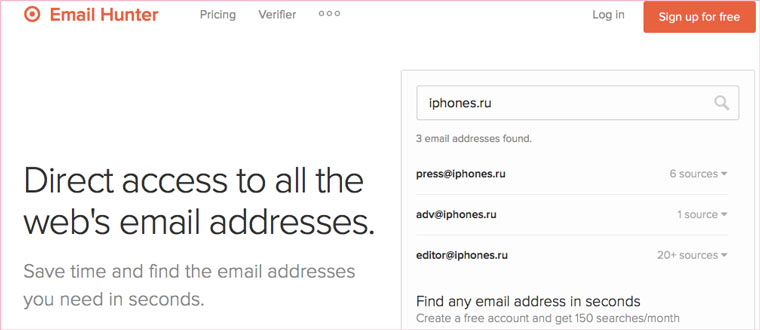
А о сборе информации про людей читайте в статьях и .
Всем привет! Недавно на почту прислали один достаточно нетривиальный вопрос - "Как найти удаленные страницы сайта, на которые ссылаются другие ресурсы?". То есть когда-то был документ, на который сослался другой проект. Потом страницу удалили (случайно или специально) либо изменили URL, и ссылка стала вести на документ с 404-ошибкой. Что делать в такой ситуации?
Прежде чем продолжить пост, хочу выразить всем огромное спасибо за поздравления с днем рождения и комментарии к ! Приятные и жизненные пожелания - очень приятно ! Результаты мини-конкурса будут подведены в конце статьи.
Молодые сайты, как правило, не страдают проблемой пропавших страниц. Это больше относится к уже старым проектам, на которых спустя долгий период что-то было удалено.
Итак, найти удаленные страницы с обратными ссылками будет полезно по нескольким причинам (тем более это бесплатно, либо с небольшими затратами). Во-первых, вы узнаете, какие документы были удалены. Впредь подобные страницы лучше не удалять (ведь они собирают линки). Во-вторых, скорее всего, на эти документы были поставлены (раз вы о них не знали; если бы знали - ничего не удаляли ). В-третьих, вы найдете некорректные линки, которые были поставлены на ваш ресурс (сможете исправить ситуацию). В-четвертых, можно будет узнать, не ставит ли никто специально обратки на разные несуществующие страницы проекта.
Сначала я задался вопрос - "Как это все сделать?". Очевидно, что нужно анализировать ссылочную массу, а точнее страницы, на которые ведет хотя бы 1 линк. Для этого есть несколько инструментов. Не в ручную же все делать!?
1. Яндекс.Вебмастер. Заходим в "Индексирование" -> "Входящие ссылки" и скачиваем архив с данными по входящей ссылочной массе.

Там будут как документы доноров, так и ваши. Единственное, файл в формате txt, поэтому для удобства работы необходимо все из него скопировать и вставить в таблицу, например, excel.
2. Google Webmaster. Практически все тоже самое проделываем и с инструментарием, который предоставляет Гугл. Заходим в "Поисковый трафик" -> "Ссылки на ваш сайт". Далее жмем "Дополнительно" в блоке "Ваши страницы, на которые чаще всего ссылаются".

Выводим показ по 500 штук. Выделяем все строки, копируем и вставляем в тот же excel, после, удалив все ненужное. Тут будет неудобный момент с подстановкой имени домена к кускам страниц (в Google Webmaster показываются только уникальные части линков). Вероятно, как-то можно удобно сделать подстановку основного домена через макрос в том же excel. Если кто-то знает расскажите, пожалуйста, в комментариях . Спасибо Profitcore за !

В итоге получаем excel-файл с 2-мя базами. Большинство вебмастеров может остановиться на этом моменте. Перфекционисты могут пойти дальше, немного заплатив за дополнительную информацию.
3. Ahrefs.com. Я думаю, что с этим сервисом многие знакомы. В отличие от первых 2-х он платный. Ahrefs также может предоставить подобную информацию. Вероятно, база ахрефс будет содержать страницы, которые не показал ни Яндекс, ни Google.

4. . Это ссылка на пост в блоге, который описывает работу сервиса. В 2-х словах - бюджетный аналог ahrefs для тех, у кого нет там платного аккаунта. База используется одна и та же, но стандартная подписка стоит 500 рублей.
В итоге получаем базу со страницами, на которые ведут ссылки с разных источников. Скорее всего, она будет содержать дубли. Чтобы не нагружать себя, свой и чужие компьютеры лишними данными, нужно их удалить. В excel 2007 года это делается очень легко. Сначала выделяем все строки (можно Ctrl+A). Затем идем в раздел "Данные" и нажимаем на "Удалить дубликаты".

В появившемся окне кликаем "Ок". Все - дубли удалены. Очень полезная функция .
Массовая проверка ответа сервера
Теперь необходимо узнать, все ли страницы нашего сайта, имеющие обратную ссылочную массу, работают как надо, либо есть те, которые отдают 404-ошибку (документ не найден). Для этого добавим наш список в один из следующих сервисов (спасибо создателям за их разработку):
- http://4seo.biz/tools/31/ - бесплатно, быстро и понятно.
- http://coolakov.ru/tools/ping/ - подольше.
- http://www.seolium.com/seo/tools/http-status-checker/ - также не особо быстро.
С помощью первого сервиса я получил 1 страницу со статусом 404.

Перехожу на нее. Действительно - "Ничего не найдено". По URL понимаю, что это относится к . Вот только ссылка неправильная. Не 10.000, а 1.000. По файлу из Яндекс.Вебмастера смотрю, откуда ведет этот линк.
Получаю 4 обратки с grabr.ru. Вероятно, когда-то я неправильно указал URL, когда давал анонс в этой социальной сети для вебмастеров .
Дальнейшие действия
Существует несколько сценариев действий, которые зависят от разных ситуаций:
- В моем случае будет уместен 301-редирект (ссылаться на уже существующий документ по другому URL). Так и сделал.
- Если ошибку совершил владелец площадки, то можно написать ему и попросить сменить адрес на корректный.
- Восстановить (если это уместно) или создать (если, например, линк с качественной площадки, а владелец не отвечает на письма) страницу по URL, который отдает 404-ошибку.
Вот таким нехитрым образом можно восстановить некоторые ссылки, которые могут быть полезны при продвижении сайта. Отличный пункт для todo-листа проекта с возрастом более 2-х лет. Не правда ли ? Это мероприятие можно проводить раз в 1-2 года, как для своих ресурсов, так и для клиентских сайтов.
Если вы знаете вариант, как проще найти подобные страницы, то напишите, пожалуйста, в комментариях. Буду рад ознакомиться. А то, может быть, изобрел велосипед .
Итоги деньрожденского мини-конкурса
Еще раз большое спасибо за ваши комментарии и поздравления! Подвожу итоги мини-конкурса. Как многие знают, в блоге стоит премодерация на комментаторов, у которых нет хотя бы одного одобренного комментария (защита от спамеров). В связи с этим та картина, которая была вчера, отличается от той, которая показывается сейчас: сегодня доодобрил все отзывы к посту.
Во-первых, это держало некоторую интригу. Во-вторых, не показывало пример очень настойчивых комментаторов . Итак, вот победители конкурса (номер комментария и имя):
13 - Бульбаш
26 - Сергей
39 - Александр
52 - Алексей
65 - fktrc
78 - albedo
Жду ваши R-кошельки, направленные с той же почты, с которой оставлялся отзыв . На сегодня все - до новых встреч!