Приложение D. Примеры SQL-запросов в MariaDB (MySQL)
Это приложение содержит более краткое описание различных команд SQL. Цель состоит в том, чтобы дать вам быструю и точную ссылку и определение SQL. Первый раздел этого приложения определяет элементы, используемые для создания команд SQL; второй, подробности синтаксиса и предложения с кратким описанием самих команд. Далее показаны стандартные условные обозначения (они называются BNF условиями):
Кроме того, мы будем использовать следующую последовательность (.,..) чтобы указывать, что предшествующее этому может повторяться любое число раз с индивидуальными событиями отделяемыми запятыми. Атрибуты которые не являются частью официального стандарта будут отмечены как (*нестандартные*) в описании.
ОБРАТИТЕ ВНИМАНИЕ: Терминология которую мы используем здесь, не официальна терминология ANSI. Официальная терминология может вас сильно запутать, поэтому мы несколько ее упростили.
По этой причине, мы иногда используем условия отличающиеся от ANSI, или используем те же самые условия но несколько по-другому. Например, наше определение - < predicate > отличается от используемой в ANSI комбинации стандартного определения < predicate > с < search condition >.
SQL ЭЛЕМЕНТЫ
Этот раздел определяет элементы команд SQL. Они разделены на две категории: Основные элементы языка , и Функциональные элементы языка .
Основные элементы - это создаваемые блоки языка; когда SQL исследует команду, то он сначала оценивает каждый символ в тексте команды в тер- минах этих элементов. Разделители< separator > отделяют одну часть команды от другой; все что находится между разделителями < separator > обрабатывается как модуль. Основываясь на этом разделении, SQL и интерпретирует команду.
Функциональные элементы - это разнообразные вещи отличающиеся от ключевых слов, которые могут интерпретироваться как модули. Это - части команды, отделяемые с помощью разделителей < separator >, имеющих специальное значение в SQL. Некоторые из них являются специальными для определенных команд и будут описаны вместе с этими командами по- зже, в этом приложении. Перечисленное здесь, является общими элементы для всех описываемых команд. Функциональные элементы могут определяться в терминах друг друга или даже в собственных терминах. Например, предикат < predicate >, наш последний и наиболее сложный случай, содержит предикат внутри собственного определения. Это потому, что предикат < predicate > использующий AND или OR может содержать любое число предикатов < predicate > которые могут работать автономно. Мы представляли вам предикат < predicate > в отдельной секции в этом приложении, из-за разнообразия и сложности этого функционального элемента языка. Он будет постоянно присутствовать при обсуждении других функциональных частей команд.
ЭЛЕМЕНТЫ ЯЗЫКА БЕЙСИКА
ЭЛЕМЕНТ ОПРЕДЕЛЕНИЕ < separator > < comment > | < space > | < newline > < comment > --< string > < newline > < space > пробел < newline > реализационно-определяемый конец символьной строки < identifier > < letter >[{< letter or digit > | < underscore}... ] < ИМЕЙТЕ ВВИДУ: Следу строгому стандарту ANSI, символы должны быть набраны в верхнем регистра, а идентификатор < identifier > не должен быть длиннее 18-ти символов. ЭЛЕМЕНТ ОПРЕДЕЛЕНИЕ < underscore > - < percent sign > % < delimiter > любое из следующих: , () < > . : = + " - | <> > = < = или < string > < string > [любой печатаемый текст в одиночных кавычках] Примечание: В < string >, две последовательных одиночных кавычки (" ") интерпретируются как одна ("). < SQL term > окончание, зависящее от главного языка. (*только вложенный*)
ФУНКЦИОНАЛЬНЫЕ ЭЛЕМЕНТЫ
Следующая таблица показывает функциональные элементы команд SQL и их определения: ЭЛЕМЕНТ ОПРЕДЕЛЕНИЕ < query > Предложение SELECT < subquery > Заключенное в круглых скобках предложение SELECT внутри другого условия, которое, фактически, оценивается отдельно для каждой строки-кандидата другого предложения. < value expression > < primary > | < primary > < operator > < primary > | < primary > < operator > < value expression > < operator > любое из следующих: + - / * < primary > < column name > | < literal > | < aggregate function > | < built-in constant > | < nonstandard function > < literal > < string > | < mathematical expressio ЭЛЕМЕНТ ОПРЕДЕЛЕНИЕ < built-in constant > USER | < implementation-dehned constant > < table name > < identifier > < column spec > [< table name > | < alias >.]< column name > < grouping column > < column spec > | < integer > < ordering column > < column spec > | < integer > < colconstraint > NOT NULL | UNIQUE | CHECK (< predicate >) | PRIMARY KEY | REFERENCES < table name >[(< column name >)] < tabconstraint > UNIQUE (< column list >) | CHECK (< predicate >) | PRIMARY KEY (< column list >) | FOREIGN KEY (< column list >) REFERENCES < table name >[(< column list >)] < defvalue > ЗНАЧЕНИЕ ПО УМОЛЧАНИЮ = < value expression > < data type > Допустимый тип данных (См. Приложение B для описания типов обеспечиваемых ANSI или Приложение C для других общих типов.) < size > Значение зависит от < data type >(См. Приложение B .) < cursor name > < identifier > < index name > < identifier > < synonym > < identifier >(*nonstandard*) < owner > < Authorization ID > < column list > < column spec > .,.. < value list > < value expression > .,.. < table reference > { < table name > [< alias >] } .,..ПРЕДИКАТЫ
Следующее определяет список различных типов предиката < predicate > описанных на следующих страницах:
< predicate > ::=
{ < comparison predicate > | < in predicate > | < null predicate > | < between predicate > | < like predicate > | < quantified predicate > | < exists predicate > } < predicate > - это выражение, которое может быть верным, неверным, или неизвестным, за исключением < exists predicate > и < null predicate >, которые могут быть только верными или неверными.
Будет получено неизвестно если NULL значения предотвращают вывод полученного ответа. Это будет случаться всякий раз, когда NULL значение сравнивается с любым значением. Стандартные операторы Буля - AND, OR, и NOT - могут использоваться с предикатом. NOT верно = неверно, NOT неверно = верно, а NOT неизвестно = неизвестно. Результаты AND и OR в комбинации с предикатами, показаны в следующих таблицах:
AND AND Верно Неверно Неизвестно Верно верно неверно неизвестно Неверно неверно неверно неверно Неизвестно неизвестно неверно неизвестно OR OR Верно Неверно Неизвестно Верно верно верно верно Неверно верно неверно неизвестно Неизвестно верно неизвестно неизвестно
Эти таблицы читаются способом наподобие таблицы умножения: вы объединяете верные, неверные, или неизвестные значения из строк с их столбцами чтобы на перекрестье получить результат. В таблице AND, например, третий столбец (Неизвестно) и первая строка (Верно) на пересечении в верхнем правом углу дают результат - неизвестно, другими словами: Верно AND Неизвестно = неизвестно. Порядок вычислений определяется круглыми скобками. Они не представляются каждый раз. NOT оценивается первым, далее AND и OR. Различные типы предикатов < predicate > рассматриваются отдельно в следующем разделе.
< comparison predicate > (предикат сравнения)
Синтаксис
< value expresslon > < relational op > < value expresslon >
|
< subquery >
< relatlonal op > :: =
=
| <
|
>
| <
| >=
| < >
Если либо < value expression > = NULL, либо < comparison predicate
> = неизвестно; другими словами, это верно если сравнение верно или неверно
если сравнение неверно.
< relational op > имеет стандартные
математические значения для числовых значений; для других типов значений, эти
значения определяются конкретной реализацией.
Оба < value expression >
должны иметь сравнимые типы данных. Если подзапрос < subquery >
используется, он должен содержать одно выражение < value expression > в
предложении SELECT, чье значение будет заменять второе выражение < value
expression > в предикате сравнения < comparision predicate >, каждый
раз когда < subquery > действительно выполняется.
< between predicate >
Синтаксис
< value expression > BETWEEN < value expression >
AND
< value expression >
< between predicate > - A BETWEEN B AND C , имеет такое же значение что и < predicate > - (A >= B AND < = C). < between predicate > для которого A NOT BETWEEN B AND C, имеет такое же значение что и NOT (BETWEEN B AND C). < value expression > может быть выведено с помощью нестандартного запроса < subquery > (*nonstandard*).
< in prediicate >
Синтаксис
< value expression > IN < value list > | < subquery
>
Список значений < value list > будет состоять из одного или более перечисленных значений в круглых скобках и отделяемых запятыми, которые имеют сравнимый с < value expression > тип данных. Если используется подзапрос < subquery >, он должен содержать только одно выражение < value expression > в предложении SELECT (возможно и больше, но это уже будет вне стандарта ANSI). Подзапрос < subquery > фактически, выполняется отдельно для каждой строки-кандидата основного запроса, и значения которые он выведет, будут составлять список значений < value list > для этой строки. В любом случае, предикат < in predicate > будет верен если выражение < value expression > представленное в списке значений < value list >, если не указан NOT. Фраза A NOT IN (B, C) является эквивалентом фразы NOT (A IN (B, C)).
< like predicate >
Синтаксис
< charvalue > LIKE < pattern >
< charvalue > - это любое *нестандартное* выражение < value expression > алфавитно-цифрового типа. < charvalue > может быть, в соответствии со стандартом, только определенным столбцом < column spec >. Образец < pattern > состоит из строки которая будет проверена на совпадение с < charvalue >. Символ окончания < escapechar > - это одиночный алфавитно-цифровой символ. Совпадение произойдет, если верны следующие условия:
Если совпадение произошло, < like predicate > - верен, если не был указан NOT. Фраза NOT LIKE "текст" - эквивалентна NOT (A LIKE "текст").
< null predicate >
Синтаксис
< column spec > IS NULL
< column spec > = IS NULL, если NULL значение представлено в этом столбце. Это сделает < null predicate > верным если не указан NULL. Фраза < column spec > IS NOT NULL, имеет тот же результат что и NOT (< column spec > IS NULL).
< quantified predicate >
Синтаксис
< value expression > < relational op >
< quantifier >
< subquery >
< quantifier > :: = ANY | ALL | SOME
Предложение SELECT подзапроса < subquery > должно содержать одно и только одно выражение значения < value expression >. Все значения выведенные подзапросом < subquery > составляют набор результатов < result set >. < value expression > сравнивается, используя оператор связи < relational operator >, с каждым членом набора результатов < result set >. Это сравнение оценивается следующим образом:
< exists predicate >
Синтаксис:
EXISTS (< subquery >)
Если подзапрос < subquery > выводит одну или более строк вывода, < exists predicate > - верен; и неверен если иначе.
SQL КОМАНДЫ
Этот раздел подробно описывает синтаксис различных команд SQL. Это даст вам возможность быстро отыскивать команду, находить ее синтаксис и краткое описание ее работы.
ИМЕЙТЕ ВВИДУ Команды которые начинаются словами - EXEC SQL, а также команды или предложения заканчивающиеся словом - могут использоваться только во вложенном SQL.
BEGIN DECLARE SECTION (НАЧАЛО РАЗДЕЛА ОБЪЯВЛЕНИЙ)
Синтаксис
EXEC SQL BEGIN DECLARE SECTION < SQL term > < host-language variable declarations > EXEC SQL END DECLARE SECTION < SQL term >
Эта команда создает раздел программы главного языка для объявления в ней главных переменных, которые будут использоваться во вкладываемых операторах SQL. Переменна SQLCODE должна быть включена как одна из объявляемых переменных главного языка.
CLOSE CURSOR (ЗАКРЫТЬ КУРСОР)
Синтаксис
EXEC SQL CLOSE CURSOR < cursor name > < SQL term >;
Эта команда указывает курсору закрыться, после чего ни одно значение не сможет быть выбрано из него до тех пор пока он не будет снова открыт.
COMMIT (WORK) (ФИКСАЦИЯ (ТРАНЗАКЦИИ))
Синтаксис
Эта команда оставляет неизменными все изменения сделанных в базе данных, до тех пор пока начавшаяся транзакция не закончится, и не начнется новая транзакция.
CREATE INDEX (СОЗДАТЬ ИНДЕКС)
(*NONSTANDARD*) (НЕСТАНДАРТНО)
Синтаксис
CREATE INDEX < Index name >
ON < table name > (<
column list >);
Эта команда создает эффективный маршрут с быстрым доступом для поиска строк содержащих обозначенные столбцы. Если UNIQUE - указана, таблица не сможет содержать дубликатов(двойников) значений в этих столбцах.
CREATE SYNONYM (*NONSTANDARD*)
(СОЗДАТЬ СИНОНИМ) (*НЕСТАНДАРТНО*)
Синтаксис
CREATE IPUBLICl SYNONYM < synonym > FOR
< owner >.< table
name >;
Эта команда создает альтернативное(синоним) им для таблицы. Синоним принадлежит его создателю, а сама таблица, обычно другому пользователю. Используя синоним, его владелец может не ссылаться к таблице ее полным (включая им владельца) именем. Если PUBLIC - указан, синоним принадлежит каталогу SYSTEM и следовательно доступен всем пользователям.
CREATE TABLE (СОЗДАТЬ ТАБЛИЦУ)
Синтаксис
CREATE TABLE < table name >
({< column name > < data type
>[< size >]
[< colconstralnt > . . .]
[< defvalue
>]} . , . . < tabconstraint > . , . .);
Команда создает таблицу в базе данных. Эта таблица будет принадлежать ее
создателю. Столбцы будут рассматриваться в поименном порядке. < data type
> - определяет тип данных который будет содержать столбец. Стандарт < data
type > описывается в Приложении
B ; все прочие используемые типы данных < data type >, обсуждались в Приложении
C . Значение размера < size > зависит от типа данных < data type
>.
< colconstraint > и < tabconstraint > налагают ограничения
на значения ко торые могут быть введены в столбцу.
< defvalue >
определяет значение(по умолчанию) которое будет вставлено автоматически, если
никакого другого значения не указано для этой строки. (См. Главу
17 для подробностей о самой команде CREATE TABLE иГлавы
18 И для
подробностей об ограничениях и о < defvalue >).
CREATE VIEW (СОЗДАТЬ ПРОСМОТР)
Синтаксис
CREATE VIEW < table name >
AS < query >
;
Просмотр обрабатывается как люба таблица в командах SQL. Когда команда
ссылается на имя таблицы < table name >, запрос < query >
выполняется, и его вывод соответствует содержанию таблицы указанной в этой
команде.
Некоторые просмотры могут модифицироваться, что означает, что
команды модификации могут выполняться в этих просмотрах и передаваться в
таблицу, на которую была ссылка в запросе < query >. Если указано
предложение WITH CHECK OPTION, эта модификация должны также удовлетворять
условию предиката < predicate > в запросе < query >.
DECLARE CURSOR (ОБЪЯВИТЬ КУРСОР)
Синтаксис
EXEC SQL DECLARE < cursor name > CURSOR FOR
< query >< SQL
term >
Эта команда связывает им курсора < cursor name >, с запросом < query >. Когда курсор открыт (см. OPEN CURSOR), запрос < query > выполняет ся, и его результат может быть выбран(командой FETCH) для вывода. Если курсор модифицируемый, таблица на которую ссылается запрос < query >, может получить изменение содержания с помощью операции модификации в курсоре (См. Главу 25 о модифицируемых курсорах).
DELETE (УДАЛИТЬ)
Синтаксис
DELETE FROM < table name >
{ ; }
|
WHERE CURRENT OF < cursorname >< SQL term >
Если предложение WHERE отсутствует, ВСЕ строки таблицы удаляются. Если предложение WHERE использует предикат < predicate >, строки, ко торые удовлетворяют условию этого предиката < predicate > удаляются. Если предложение WHERE имеет аргумент CURRENT OF(ТЕКУЩИЙ) в имени курсора < cursor name >, строка из таблицы < table name > на ко торую в данный момент имеется ссылка с помощью имени курсора < cursor name > будет удалена. Форма WHERE CURRENT может использоваться только во вложенном SQL, и только с модифицируемыми курсорами.
EXEC SQL (ВЫПОЛНИТЬ SQL)
Синтаксис
EXEC SQL < embedded SQL command > < SQL term >
EXEC SQL используется чтобы указывать начало всех команд SQL, вложенных в другой язык.
FETCH (ВЫБОРКА)
Синтаксис
EXEC SQL FETCH < cursorname >
INTO < host-varlable llst ><
SQL term >
FETCH принимает вывод из текущей строки запроса < query >, вставляет ее в список главных переменных < host-variable list >, и перемещает кур сор на следующую строку. Список < host-variable list > может включать переменную indicator в качестве целевой переменной (См. Главу 25 .)
GRANT (ПЕРЕДАТЬ ПРАВА)
Синтаксис (стандартный)
GRANT ALL
| {SELECT
| INSERT
| DELETE
| UPDATE
[(< column llst >)]
| REFERENCES [(< column llst >)l } . , . .
ON < table name > . , . .
TO PUBLIC | < Authorization ID > .
, . .
;
Аргумент ALL(ВСЕ), с или без PRIVILEGES(ПРИВИЛЕГИИ), включает каждую привилегию в список привилегий. PUBLIC(ОБЩИЙ) включает всех существующих пользователей и всех созданных в будущем. Эта команда дает возможность передать права для выполнения действий в таблице с указанным именем. REFERENCES позволяет дать права чтобы использовать столбцы в списке столбцов < column list > как родительский ключ для внешнего ключа. Другие привилегии состоят из права выполнять команды для которых привилегии указаны их именами в таблице. UPDATE, подобен REFERENCES, и может накладывать ограничения на определенные столбцы. GRANT OPTION дает возможность передавать эти привилегии другим пользователям.
Синтаксис (нестандартный)
GRANT DBA
| RESOURCE
| CONNECT ... .
TO < Authorization ID
> . , . .
| < privilege > . , . . }
FROM { PUBLIC
| < Authorization ID > . , . . };
Привилегия < privelege > может быть любой из указанных в команде GRANT. Пользователь дающий REVOKE должен иметь те же привилегии, что и пользователь который давал GRANT. Предложение ON может быть использовано, если используется привилегия специального типа для особого объекта.
ROLLBACK (WORK)
(ОТКАТ) (ТРАНЗАКЦИИ)
Синтаксис
Команда отменяет все изменения в базе данных, сделанные в течение те- кущей транзакции. Она кроме того заканчивается текущую, и начинает новую транзакцию.
SELECT (ВЫБОР)
Синтаксис
SELECT { IDISTINCT | ALL] < value expression > . , . . } / *
FROM < table reference
> . , . .
. , . . ];
Это предложение организует запрос и выводит значения из базы данных (см. Глава 3 - Глава 14). Применяются следующие правила:
Предложение SELECT оценивает каждую строку-кандидат таблицы в которой строки показаны независимо. Строка-кандидат определяется следующим образом:
Каждая строка-кандидат производит значения, которые делают предикат <
predicate > в предложении WHERE верным, неверным, или неизвестным. Если GROUP
BY не используется, каждое < value expression > применяется в свою очередь
для каждой строки-кандидата чье значение делает предикат верным, и результатом
этой операции является вывод.
Если GROUP BY используется, строки-кандидаты
комбинируются, используя агрегатные функции. Если никакого предиката <
predicate > не установлено, каждое выражение< value expression >
применяется к каждой строке-кандидату или к каждой группе. Если указан DISTINCT,
дубликаты(двойники) строк будут удалены из вывода.
UNION (ОБЪЕДИНЕНИЕ)
Синтаксис
< query > {UNION < query > } . . . ;
Вывод двух или более запросов < query > будет объединен. Каждый запрос < query > должен содержать один и тот же номер < value expression > в предложение SELECT и в таком порядке что 1.. n каждого, совместим по типу данных < data type > и размеру < size > с 1.. n всех других.
UPDATE (МОДИФИКАЦИЯ)
Синтаксис
UPDATE < table name >
SET { < column name > = < value
expression > } . , . .
{[ WHERE < predlcate >]; }
| {
< SQL term >]}
UPDATE изменяет значения в каждом столбце с именем < column name > на соответствующее значение < value expression >. Если предложение WHERE использует предикат < predicate >, то только строки таблиц чьи текущие значения делают тот предикат < predicate > верным, могут быть изменены. Если WHERE использует предложение CURRENT OF, то значения в строке таблицы с именем < table name > находящиеся в курсоре с именем < cursor name > меняются. WHERE CURRENT OF пригодно для использования только во вложенном SQL, и только с модифицируемыми курсорами. При отсутствии предложения WHERE - все строки меняются.
WHENEVER (ВСЯКИЙ РАЗ КАК)
Синтаксис
EXEC SQL WHENEVER < SQLcond > < actlon > < SQL term
>
< SQLcond > :: = SQLERROR | NOT FOUND | SQLWARNING
(последнее
- нестандартное)
< action > :: = CONTINUE | GOTO < target > |
GOTO < target >
< target > :: = зависит от главного языка
Табличными выражениями называются подзапросы, которые используются там, где ожидается наличие таблицы. Существует два типа табличных выражений:
производные таблицы;
обобщенные табличные выражения.
Эти две формы табличных выражений рассматриваются в следующих подразделах.
Производные таблицы
Производная таблица (derived table) - это табличное выражение, входящее в предложение FROM запроса. Производные таблицы можно применять в тех случаях, когда использование псевдонимов столбцов не представляется возможным, поскольку транслятор SQL обрабатывает другое предложение до того, как псевдоним станет известным. В примере ниже показана попытка использовать псевдоним столбца в ситуации, когда другое предложение обрабатывается до того, как станет известным псевдоним:
USE SampleDb; SELECT MONTH(EnterDate) as enter_month FROM Works_on GROUP BY enter_month;
Попытка выполнить этот запрос выдаст следующее сообщение об ошибке:
Msg 207, Level 16, State 1, Line 5 Invalid column name "enter_month". (Сообщение 207: уровень 16, состояние 1, строка 5 Недопустимое имя столбца enter_month)
Причиной ошибки является то обстоятельство, что предложение GROUP BY обрабатывается до обработки соответствующего списка инструкции SELECT, и при обработке этой группы псевдоним столбца enter_month неизвестен.
Эту проблему можно решить, используя производную таблицу, содержащую предшествующий запрос (без предложения GROUP BY), поскольку предложение FROM исполняется перед предложением GROUP BY:
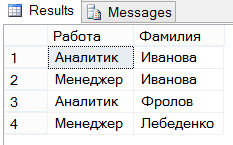
USE SampleDb; SELECT enter_month FROM (SELECT MONTH(EnterDate) as enter_month FROM Works_on) AS m GROUP BY enter_month;
Результат выполнения этого запроса будет таким:
Обычно табличное выражение можно разместить в любом месте инструкции SELECT, где может появиться имя таблицы. (Результатом табличного выражения всегда является таблица или, в особых случаях, выражение.) В примере ниже показывается использование табличного выражения в списке выбора инструкции SELECT:
Результат выполнения этого запроса:
Обобщенные табличные выражения
Обобщенным табличным выражением (OTB) (Common Table Expression - сокращенно CTE) называется именованное табличное выражение, поддерживаемое языком Transact-SQL. Обобщенные табличные выражения используются в следующих двух типах запросов:
нерекурсивных;
рекурсивных.
Эти два типа запросов рассматриваются в следующих далее разделах.
OTB и нерекурсивные запросы
Нерекурсивную форму OTB можно использовать в качестве альтернативы производным таблицам и представлениям. Обычно OTB определяется посредством предложения WITH и дополнительного запроса, который ссылается на имя, используемое в предложении WITH. В языке Transact-SQL значение ключевого слова WITH неоднозначно. Чтобы избежать неопределенности, инструкцию, предшествующую оператору WITH, следует завершать точкой с запятой.
USE AdventureWorks2012; SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE TotalDue > (SELECT AVG(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = "2005") AND Freight > (SELECT AVG(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = "2005")/2.5;
Запрос в этом примере выбирает заказы, чьи общие суммы налогов (TotalDue) большие, чем среднее значение по всем налогам, и плата за перевозку (Freight) которых больше чем 40% среднего значения налогов. Основным свойством этого запроса является его объемистость, поскольку вложенный запрос требуется писать дважды. Одним из возможных способов уменьшить объем конструкции запроса будет создать представление, содержащее вложенный запрос. Но это решение несколько сложно, поскольку требует создания представления, а потом его удаления после окончания выполнения запроса. Лучшим подходом будет создать OTB. В примере ниже показывается использование нерекурсивного OTB, которое сокращает определение запроса, приведенного выше:
USE AdventureWorks2012; WITH price_calc(year_2005) AS (SELECT AVG(TotalDue) FROM Sales.SalesOrderHeader WHERE YEAR(OrderDate) = "2005") SELECT SalesOrderID FROM Sales.SalesOrderHeader WHERE TotalDue > (SELECT year_2005 FROM price_calc) AND Freight > (SELECT year_2005 FROM price_calc)/2.5;
Синтаксис предложения WITH в нерекурсивных запросах имеет следующий вид:
Параметр cte_name представляет имя OTB, которое определяет результирующую таблицу, а параметр column_list - список столбцов табличного выражения. (В примере выше OTB называется price_calc и имеет один столбец - year_2005.) Параметр inner_query представляет инструкцию SELECT, которая определяет результирующий набор соответствующего табличного выражения. После этого определенное табличное выражение можно использовать во внешнем запросе outer_query. (Внешний запрос в примере выше использует OTB price_calc и ее столбец year_2005, чтобы упростить употребляющийся дважды вложенный запрос.)
OTB и рекурсивные запросы
В этом разделе представляется материал повышенной сложности. Поэтому при первом его чтении рекомендуется его пропустить и вернуться к нему позже. Посредством OTB можно реализовывать рекурсии, поскольку OTB могут содержать ссылки на самих себя. Основной синтаксис OTB для рекурсивного запроса выглядит таким образом:
Параметры cte_name и column_list имеют такое же значение, как и в OTB для нерекурсивных запросов. Тело предложения WITH состоит из двух запросов, объединенных оператором UNION ALL . Первый запрос вызывается только один раз, и он начинает накапливать результат рекурсии. Первый операнд оператора UNION ALL не ссылается на OTB. Этот запрос называется опорным запросом или источником.
Второй запрос содержит ссылку на OTB и представляет ее рекурсивную часть. Вследствие этого он называется рекурсивным членом. В первом вызове рекурсивной части ссылка на OTB представляет результат опорного запроса. Рекурсивный член использует результат первого вызова запроса. После этого система снова вызывает рекурсивную часть. Вызов рекурсивного члена прекращается, когда предыдущий его вызов возвращает пустой результирующий набор.
Оператор UNION ALL соединяет накопившиеся на данный момент строки, а также дополнительные строки, добавленные текущим вызовом рекурсивного члена. (Наличие оператора UNION ALL означает, что повторяющиеся строки не будут удалены из результата.)
Наконец, параметр outer_query определяет внешний запрос, который использует OTB для получения всех вызовов объединения обеих членов.
Для демонстрации рекурсивной формы OTB мы используем таблицу Airplane, определенную и заполненную кодом, показанным в примере ниже:
USE SampleDb; CREATE TABLE Airplane (ContainingAssembly VARCHAR(10), ContainedAssembly VARCHAR(10), QuantityContained INT, UnitCost DECIMAL (6,2)); INSERT INTO Airplane VALUES ("Самолет", "Фюзеляж",1, 10); INSERT INTO Airplane VALUES ("Самолет", "Крылья", 1, 11); INSERT INTO Airplane VALUES ("Самолет", "Хвост",1, 12); INSERT INTO Airplane VALUES ("Фюзеляж", "Салон", 1, 13); INSERT INTO Airplane VALUES ("Фюзеляж", "Кабина", 1, 14); INSERT INTO Airplane VALUES ("Фюзеляж", "Нос",1, 15); INSERT INTO Airplane VALUES ("Салон", NULL, 1,13); INSERT INTO Airplane VALUES ("Кабина", NULL, 1, 14); INSERT INTO Airplane VALUES ("Нос", NULL, 1, 15); INSERT INTO Airplane VALUES ("Крылья", NULL,2, 11); INSERT INTO Airplane VALUES ("Хвост", NULL, 1, 12);
Таблица Airplane состоит из четырех столбцов. Столбец ContainingAssembly определяет сборку, а столбец ContainedAssembly - части (одна за другой), которые составляют соответствующую сборку. На рисунке ниже приведена графическая иллюстрация возможного вида самолета и его составляющих частей:

Таблица Airplane состоит из следующих 11 строк:

В примере ниже показано применение предложения WITH для определения запроса, который вычисляет общую стоимость каждой сборки:
USE SampleDb; WITH list_of_parts(assembly1, quantity, cost) AS (SELECT ContainingAssembly, QuantityContained, UnitCost FROM Airplane WHERE ContainedAssembly IS NULL UNION ALL SELECT a.ContainingAssembly, a.QuantityContained, CAST(l.quantity * l.cost AS DECIMAL(6,2)) FROM list_of_parts l, Airplane a WHERE l.assembly1 = a.ContainedAssembly) SELECT assembly1 "Деталь", quantity "Кол-во", cost "Цена" FROM list_of_parts;
Предложение WITH определяет список OTB с именем list_of_parts, состоящий из трех столбцов: assembly1, quantity и cost. Первая инструкция SELECT в примере вызывается только один раз, чтобы сохранить результаты первого шага процесса рекурсии. Инструкция SELECT в последней строке примера отображает следующий результат.
Содержание статьи
1.
Самые простые MySQL запросы
2.
Простые SELECT (выбрать) запросы
3.
Простые INSERT (новая запись) запросы
4.
Простые UPDATE (перезаписать, дописать) запросы
5.
Простые DELETE (удалить запись) запросы
6.
Простые DROP (удалить таблицу) запросы
7.
Сложные MySQL запросы
8.
MySQL запросы и переменные PHP
1. Самые простые SQL запросы
1. Выведет список ВСЕХ баз.SHOW databases;
2. Выведет список ВСЕХ таблиц в Базе Данных base_name.
SHOW tables in base_name;
2. Простые SELECT (выбрать) запросы к базе данных MySQL
SELECT – запрос, который выбирает уже существующие данные из БД. Для выбора можно указывать определённые параметры выбора. Например, суть запроса русским языком звучит так - ВЫБРАТЬ такие-то колонки ИЗ такой-то таблицы ГДЕ параметр такой-то колонки равен значению.1. Выбирает ВСЕ данные в таблице tbl_name.
SELECT * FROM tbl_name;
2. Выведет количество записей в таблице tbl_name.
SELECT count(*) FROM tbl_name;
3. Выбирает (SELECT) из(FROM) таблицы tbl_name лимит (LIMIT) 3 записи, начиная с 2.
SELECT * FROM tbl_name LIMIT 2,3;
4. Выбирает (SELECT) ВСЕ (*) записи из (FROM) таблицы tbl_name и сортирует их (ORDER BY) по полю id по порядку.
SELECT * FROM tbl_name ORDER BY id;
5. Выбирает (SELECT) ВСЕ записи из (FROM) таблицы tbl_name и сортирует их (ORDER BY) по полю id в ОБРАТНОМ порядке.
SELECT * FROM tbl_name ORDER BY id DESC;
6. Выбирает (SELECT
) ВСЕ (*) записи из (FROM
) таблицы users
и сортирует их (ORDER BY
) по полю id
в порядке возрастания, лимит (LIMIT
) первые 5 записей.
SELECT * FROM users ORDER BY id LIMIT 5;
7. Выбирает все записи из таблицы users
, где поле fname
соответствует значению Gena
.
SELECT * FROM users WHERE fname="Gena";
8. Выбирает все записи из таблицы users
, где значение поля fname
начинается с Ge
.
SELECT * FROM users WHERE fname LIKE "Ge%";
9. Выбирает все записи из таблицы users
, где fname
заканчивается на na
, и упорядочивает записи в порядке возрастания значения id
.
SELECT * FROM users WHERE fname LIKE "%na" ORDER BY id;
10. Выбирает все данные из колонок fname
, lname
из таблице users
.
SELECT fname, lname FROM users;
11.
Допустим у Вас в таблице пользовательских данных есть страна. Так вот если Вы хотите вывести ТОЛЬКО список встречающихся значений (чтобы, например, Россия не выводилось 20 раз, а только один), то используем DISTINCT. Выведет, из массы повторяющихся значений Россия, Украина, Беларусь. Таким образом, из таблицы users
колонки country
будут выведены ВСЕ УНИКАЛЬНЫЕ значения
SELECT DISTINCT country FROM users;
12. Выбирает ВСЕ данные строк из таблицы users
где age
имеет значения 18,19 и 21.
SELECT * FROM users WHERE age IN (18,19,21);
13.
Выбирает МАКСИМАЛЬНОЕ значение age
в таблице users
. То есть если у Вас в таблице самое большее значение age
(с англ. возраст) равно 55, то результатом запроса будет 55.
SELECT max(age) FROM users;
14. Выберет данные из таблицы users
по полям name
и age
ГДЕ age
принимает самое маленькое значение.
SELECT name, min(age) FROM users;
15. Выберет данные из таблицы users
по полю name
ГДЕ id
НЕ РАВЕН 2.
SELECT name FROM users WHERE id!="2";
3. Простые INSERT (новая запись) запросы
INSERT – запрос, который позволяет ПЕРВОНАЧАЛЬНО вставить запись в БД. То есть создаёт НОВУЮ запись (строчку) в БД.1. Делает новую запись в таблице users , в поле name вставляет Сергей, а в поле age вставляет 25. Таким образом, в таблицу дописывается новая строки с данными значениями. Если колонок больше, то они оставшиеся останутся либо пустыми, либо с установленными по умолчанию значениями.
INSERT INTO users (name, age) VALUES ("Сергей", "25");
4. Простые UPDATE запросы к базе данных MySQL
UPDATE – запрос, который позволяет ПЕРЕЗАПИСАТЬ значения полей или ДОПИСАТЬ что-то в уже существующей строке в БД. Например, есть готовая строка, но в ней нужно перезаписать параметр возраста, так как он изменился со временем.1. В таблице users age становится 18.
UPDATE users SET age = "18" WHERE id = "3";
2.
Всё то же самое, что и в первом запросе, просто показан синтаксис запроса, где перезаписываются два поля и более.
В таблице users
ГДЕ id равно 3 значение поля age
становится 18, а country
Россия.
UPDATE users SET age = "18", country = "Россия" WHERE id = "3";
5. Простые DELETE (удалить запись) запросы к базе данных MySQL
DELETE – запрос, который удаляет строку из таблицы.1. Удаляет строку из таблицы users ГДЕ id равен 10.
DELETE FROM users WHERE id = "10";
6. Простые DROP (удалить таблицу) запросы к базе данных MySQL
DROP – запрос, который удаляет таблицу.1. Удаляет целиком таблицу tbl_name .
DROP TABLE tbl_name;
7. Сложные запросы к базе данных MySQL
Любопытные запросы, которые могут пригодиться даже опытным пользователямSELECT id,name,country FROM users,admins WHERE TO_DAYS(NOW()) - TO_DAYS(registration_date) <= 14 AND activation != "0" ORDER BY registration_date DESC;
Данный сложный запрос ВЫБИРАЕТ колонки id,name,country
В ТАБЛИЦАХ users,admins
ГДЕ registration_date
(дата) не старше 14
дней И activation
НЕ РАВНО 0
, СОРТИРОВАТЬ по registration_date
в обратном порядке (новое в начале).
UPDATE users SET age = "18+" WHERE age = (SELECT age FROM users WHERE male = "man");
Выше указан пример так называемого запроса в запросе
в SQL. Обновить возраст среди пользователей на 18+, где пол - мужской. Подобные варианты запроса не рекомендую. По личному опыту скажу, лучше создать несколько отдельных - они будут прорабатываться быстрее.
8. Запросы к базе данных MySQL и PHP
В MySQL запросы в PHP странице можно вставлять переменные в качестве сравниваемых и тп значений. Пара примеров1. Выбирает все записи из таблицы users , где поле fname соответствует значению переменной $name .
SELECT * FROM users WHERE fname="$name";
2. В таблице users
ГДЕ id равно 3 значение поля age
изменяется на значение переменной $age.
UPDATE users SET age = "$age" WHERE id = "3";
Внимание! Если Вам интересен какой-либо ещё пример, то пишите вопрос в комментарии!
Adobe AIR включает компонент SQL Database Engine с поддержкой локальных баз данных SQL и многими стандартными возможностями SQL на основе системы баз данных с открытым кодом. Среда выполнения не определяет способ хранения данных баз данных и их расположение в файловой системе. Каждая база данных целиком хранится в одной файле. Разработчик может указать местоположение в файловой системе для хранения файла базы данных, и отдельное приложение AIR сможет получить доступ к одной или нескольким отдельным базам данных (т.е. отдельным файлам баз данных).
В данном документе описан синтаксис SQL и поддержка типов данных для локальных баз данных SQL Adobe AIR. Этот документ не претендует на роль исчерпывающего справочника по SQL. Наоборот, в нем приводятся конкретные сведения о диалекте SQL, поддерживаемом Adobe AIR. Среда выполнения поддерживает большую часть стандартного диалекта SQL-92. Поскольку существует большое число справочников, веб-узлов, книг и учебных материалов для изучения SQL, данный документ не следует рассматривать, как исчерпывающий справочник по SQL или учебник. Более того, этот документ посвящен, в частности, синтаксису SQL, поддерживаемому Apollo AIR, а также описывает различия между SQL-92 и поддерживаемым диалектом SQL.
Рассматриваются следующие темы:
Поддерживаемый синтаксис SQL
Этот раздел посвящен синтаксису SQL, поддерживаемому компонентом SQL Database Engine Adobe AIR. Приведенный список можно разделить на описания различных инструкций и типов предложений, выражений, встроенных функций и операторов. Рассматриваются следующие темы:
Общий синтаксис SQL
В дополнение к определенному синтаксису для различных инструкций и выражений применяются следующие общие правила синтаксиса SQL:
Инструкции обработки данных
Инструкции обработки данных являются наиболее часто используемыми инструкциями SQL. Эти инструкции служат для извлечения, добавления, изменения и удаления данных из таблиц баз данных. Поддерживаются следующие инструкции обработки данных:
SELECT
Инструкция SELECT служит для опроса базы данных. Результатом инструкции SELECT является ноль или несколько строк данных, где у каждой строки имеется фиксированное число столбцов. Число столбцов в результате определяется именем столбца result или списком выражений между SELECT и необязательным ключевым словом FROM .
Sql-statement::= SELECT result * ] result::= result-column [, result-column]* result-column::= * | table-name . * | expr [ string] table-list::= table [ join-op table join-args ]* table::= table-name | (select) join-op::= , | JOIN join-args::= compound-op::= UNION | UNION ALL | INTERSECT | EXCEPT sort-expr-list::= expr [, expr ]* sort-order::= collation-name::= BINARY | NOCASE
В качестве результата можно использовать любое произвольное выражение. Если результирующее выражение — * , то все столбцы всех таблиц заменяются этим выражением. Если выражение содержит имя таблицы после.* , то результатом будут все столбцы в этой таблице.
По ключевому слову DISTINCT возвращается подмножество строк результатов с разными строками результатов. Значения NULL не рассматриваются как отличные друг от друга. По умолчанию возвращаются все строки результатов, если явным образом использовать ключевое слово ALL .
Запрос выполняется по одной или нескольким таблицам, указанным после ключевого слова FROM . Если несколько имен таблиц разделены запятыми, запрос использует перекрестное соединение различных таблиц. Синтаксис JOIN можно также использовать для указания способа соединения таблиц. Поддерживаемый тип внешнего соединения — LEFT OUTER JOIN . Выражение предложения ON в join-args должно приводить к логическому значению. Вложенный запрос в скобках можно использовать как таблицу в предложении FROM . Предложение FROM можно полностью опустить, в случае чего результатом будет отдельная строка значений списка выражений result .
Предложение WHERE служит для ограничения числа строк, извлекаемых запросом. Выражения предложения WHERE должны приводить к логическому значению. Фильтрация по предложению WHERE выполняется перед всякой группировкой, поэтому в выражениях предложения WHERE не может быть статических функций.
Предложение GROUP BY приводит к объединению одной или нескольких строк результатов в одну строку результата. Предложение GROUP BY особенно полезно, если результат содержит статические функции. Выражения в предложении GROUP BY не должны быть выражениями из списка выражений SELECT .
Предложение HAVING похоже на WHERE тем, что оно ограничивает строки, возвращаемые инструкцией. При этом предложение HAVING применяется после выполнения любой группировки, заданной предложением GROUP BY . Следовательно, выражение HAVING может относиться к значениям со статическими функциями. Выражение предложения HAVING не обязательно должно присутствовать в списке SELECT . Как и выражение WHERE , выражение HAVING должно приводить к логическому значению.
Предложение ORDER BY вызывает сортировку выходных строк. Аргумент sort-expr-list в предложении ORDER BY представляет собой список выражений, используемых в качестве ключа для списка. Выражения не должны быть частью результата простой инструкции SELECT , но в составной инструкции SELECT (SELECT с использованием одного из операторов compound-op) каждое выражение сортировки должно в точности соответствовать одному из столбцов результатов. После каждого выражения сортировки можно использовать предложение sort-order (необязательно), состоящее из ключевого слова COLLATE и имени функции сортировки, используемое для упорядочивания текста, и/или ключевое слово ASC или DESC для указания порядка сортировки (по возрастанию или убыванию). Предложение sort-order можно опустить и использовать значение по умолчанию (упорядочивание по возрастанию). Определение предложения COLLATE и функций сортировки см. в разделе .
Предложение LIMIT устанавливает верхнюю границу числа строк, возвращаемых в результате. Отрицательное значение LIMIT указывает на отсутствие верхней границы. Необязательный оператор OFFSET после LIMIT указывает количество пропускаемых строк в начале результирующего набора. В составном запросе SELECT предложение LIMIT может только следовать за конечным оператором SELECT , и ограничение применяется к запросу целиком. Обратите внимание, что при использовании в предложении LIMIT ключевого слова OFFSET предельным значением является первое целое число, а смещением — второе целое число. Если вместо ключевого слова OFFSET использовать запятую, то смещением будет первое число, а предельным значением — второе число. Такое внешнее противоречие является намеренным: оно позволяет достичь максимальной совместимости с устаревшими системами баз данных SQL.
Составная инструкция SELECT формируется из одной или нескольких инструкций SELECT , соединенных одним из операторов UNION , UNION ALL , INTERSECT или EXCEPT . В составной инструкции SELECT все входящие в нее инструкции SELECT должны указывать то же число столбцов результатов. После конечной инструкции SELECT может быть только одно предложение ORDER BY (и перед отдельным предложением LIMIT , если оно указано). Операторы UNION и UNION ALL объединяют результаты предшествующих и последующих инструкции SELECT в одну таблицу. Отличие заключается в том, что в UNION различными являются все строки результатов, а в UNION ALL возможны повторения. Оператор INTERSECT принимает пересечение результатов предшествующих и последующих инструкций SELECT . EXCEPT принимает результат предшествующей инструкции SELECT после удаления результатов последующей инструкции SELECT . При соединении трех и более инструкций SELECT для образования составной инструкции, они группируются от первой до последней.
Определение разрешенных выражений см. в разделе
INSERT
Инструкция INSERT имеет две базовых формы и служит для заполнения таблиц данными.
Sql-statement::= INSERT INTO table-name [(column-list)] VALUES (value-list) | INSERT INTO table-name [(column-list)] select-statement REPLACE INTO table-name [(column-list)] VALUES (value-list) | REPLACE INTO table-name [(column-list)] select-statement
Первая форма (с ключевым словом VALUES) создает новую отдельную строку в существующей таблице. Если column-list не указан, то число значений должно соответствовать числу столбцов в таблице. Если column-list указан, то число значений должно соответствовать числу указанных столбцов. Столбцы таблицы, отсутствующие в списке столбцов, заполняются значением по умолчанию, определенным при создании таблицы, или значением NULL , если значение по умолчанию не определено.
Вторая форма INSERT берет свои данные из инструкции SELECT . Число столбцов в результате SELECT должно в точности соответствовать числу столбцов в таблице, если column-list не указан, или должно соответствовать числу столбцов, чьи имена указаны в column-list . Для каждой строки результата SELECT создается новая запись в таблице. Инструкция SELECT может быть простой или составной. Определение допустимых инструкций SELECT см. в разделе .
Две формы инструкции — REPLACE INTO — эквиваленты использованию стандартной инструкции INSERT с алгоритмом конфликтов REPLACE (т.е., форма INSERT OR REPLACE...).
UPDATE
Инструкция UPDATE служит для изменения значения столбцов в наборе строк в таблице.
Sql-statement::= UPDATE table-name SET assignment [, assignment]* conflict-algorithm::= ROLLBACK | ABORT | FAIL | IGNORE | REPLACE assignment::= column-name = expr
Каждое назначение в инструкции UPDATE указывает имя столбца слева от знака равенства (=) и произвольное выражение справа. В выражении можно использовать значения других столбцов. Перед любым назначением все выражения вычисляются. Определение разрешенных выражений см. в разделе
Предложение WHERE служит для ограничения обновляемых строк. Выражение предложения WHERE должно приводить к логическому значению.
Необязательный conflict-algorithm позволяет указывать альтернативный алгоритм разрешения конфликтов ограничений во время этой команды. Определение и описание алгоритмов конфликтов см. в разделе .
DELETE
Команда удаления служит для удаления записей из таблицы.
Sql-statement::= DELETE FROM table-name
Команда состоит из ключевых слов DELETE FROM , после которых указывается имя таблицы, из которой требуется удалить записи.
Без предложения WHERE удаляются все строки таблицы. Если предложение WHERE указано, то удаляются только те строки, которые соответствуют выражению. Выражение предложения WHERE должно приводить к логическому значению. Определение разрешенных выражений см. в разделе .
Инструкции определения данных
Инструкции определения данных служат для создания, изменения и удаления объектов баз данных, таких как таблицы, представления индексы и триггеры. Поддерживаются следующие инструкции определения данных:
CREATE TABLE
Инструкция CREATE TABLE состоит из ключевых слов CREATE TABLE с именем новой таблицы, а затем (в скобках) списком определений столбцов и ограничений. Имя таблицы может быть идентификатором или строкой.
Sql-statement::= CREATE TABLE table-name (column-def [, column-def]* [, constraint]*) sql-statement::= CREATE TABLE table-name AS select-statement column-def::= name [ column-constraint]* type::= typename | typename (number) | typename (number , number) column-constraint::= NOT NULL [ conflict-clause ] | PRIMARY KEY [ conflict-clause ] | UNIQUE | CHECK (expr) | DEFAULT default-value | COLLATE collation-name constraint::= PRIMARY KEY (column-list) | UNIQUE (column-list) | CHECK (expr) conflict-clause::= ON CONFLICT conflict-algorithm conflict-algorithm::= ROLLBACK | ABORT | FAIL | IGNORE | REPLACE default-value::= NULL | string | number | CURRENT_TIME | CURRENT_DATE | CURRENT_TIMESTAMP sort-order::= ASC | DESC collation-name::= BINARY | NOCASE column-list::= column-name [, column-name]*
Каждое определение столбца представляет имя столбца, после которого указан тип данных этого столбца, а затем одно или несколько необязательных ограничений столбца. Тип данных для столбца ограничивает тип данных, которые столбец может хранить. При попытке сохранения значения другого типа данных в столбце среда выполнения преобразует значение в соответствующие тип (если возможно) или создаст ошибку. Дополнительные сведения см. в разделе .
Ограничение столбца NOT NULL указывает, что в столбце не могут содержаться значения NULL .
Ограничение UNIQUE вызывает создание индекса для заданного столбца или столбцов. Этот индекс должен содержать уникальные ключи — две строки не могут содержать одинаковые значения или сочетания значений для заданного столбца или столбцов. Инструкция CREATE TABLE может иметь несколько ограничений UNIQUE , в том числе несколько столбцов с ограничением UNIQUE в определении столбца и/или несколько ограничений UNIQUE уровня таблицы.
Ограничение CHECK определяет вычисляемое выражение и должно быть истинным (true) для вставки или обновления данных строки. Выражение CHECK должно приводить к логическому значению.
Предложение COLLATE в определении столбца задает функцию сортировки текста, которая будет использоваться при сравнении текстовых записей для столбца. По умолчанию используется функция сортировки BINARY . Подробные сведения о предложении COLLATE и функциях сортировки см. в разделе .
Ограничение DEFAULT задает значение по умолчанию, используемое при выполнении INSERT . Значение может быть NULL , строковой константой или числом. Значение по умолчанию может также быть специальным независимым от регистра ключевым словом CURRENT_TIME , CURRENT_DATE или CURRENT_TIMESTAMP . Если значение равно NULL , является строковой константой или числом, оно буквально вставляется в столбец, если значение для столбца не задано инструкцией INSERT . Если используется значение CURRENT_TIME , CURRENT_DATE или CURRENT_TIMESTAMP , в столбец вставляется текущая дата и/или время в формате UTC. Для CURRENT_TIME задается формат HH:MM:SS . Для CURRENT_DATE форматом является YYYY-MM-DD . Формат для CURRENT_TIMESTAMP — YYYY-MM-DD HH:MM:SS .
Указание PRIMARY KEY обычно создает индекс UNIQUE для соответствующего столбца или столбцов. При этом если ограничение PRIMARY KEY действует для отдельного столбца с типом данных INTEGER , то столбец используется внутренне в качестве фактического первичного ключа для таблицы. Это означает, что в столбце могут содержаться только уникальные целочисленные значения. Если в таблице отсутствует столбец INTEGER PRIMARY KEY , ключ целых значений будет автоматически создан при вставке строки. Доступ к первичному ключу строки можно всегда получить при помощи одного из специальных имен ROWID , OID или _ROWID_ . Эти имена можно использовать независимо от того, явно объявленный INTEGER PRIMARY KEY это ключ или внутреннее созданное значение. Столбец INTEGER PRIMARY KEY может также включать ключевое слово AUTOINCREMENT . Когда используется ключевое слово AUTOINCREMENT , база данных автоматически создает и вставляет последовательно увеличивающийся ключ целых значений в столбец INTEGER PRIMARY KEY при выполнении инструкции INSERT .
В инструкции CREATE TABLE может быть только одно ограничение PRIMARY KEY . Оно может быть частью определения одного столбца или одного отдельного ограничения PRIMARY KEY уровня таблицы. Столбец первичного ключа неявно NOT NULL .
Необязательный conflict-clause после многих ограничений позволяет указывать альтернативный алгоритм разрешения конфликтов ограничений по умолчанию для такого ограничения. По умолчанию это ABORT . Для различных ограничений в одной и той же таблице возможны разные алгоритмы разрешения конфликтов по умолчанию. Если инструкция INSERT или UPDATE задает другой алгоритм разрешения конфликтов, то он используется вместо алгоритма, указанного в инструкции CREATE TABLE. Дополнительные сведения см. в разделе .
Дополнительные ограничения, такие как FOREIGN KEY, не приводят к ошибке, но среда выполнения пропускает их.
Если ключевое слово TEMP или TEMPORARY стоит между CREATE и TABLE , то создаваемая таблица будет видимой только в рамках одного и того же подключения к базе данных (экземпляр SQLConnection). При закрытии подключения она автоматически удаляется. Любые индексы, созданные во временной таблице, также являются временными. Временные таблицы и индексы хранятся в отдельном файле, отличным от основного файла базы данных.
Если указан необязательный префикс database-name , то таблица создается в именованной базе данных (базе данных, подключенной к экземпляру SQLConnection путем вызова метода attach() с заданным именем базы данных). Ошибочным будет указание префикса database-name и ключевого слова TEMP , если префикс database-name не является temp . Если имя базы данных не указано, а ключевое слово TEMP присутствует, то таблица создается в основной базе данных (базе данных, подключенной к экземпляру SQLConnection при помощи метода open() или openAsync()).
Не существует произвольных пределов на число столбцов или ограничений в таблице. Также отсутствует произвольный предел на объем данных в строке.
Форма CREATE TABLE AS определяет таблицу как результирующий набор запроса. Имена столбцов таблицы — это имена столбцов в результате.
Если присутствует необязательное предложение IF NOT EXISTS и другая таблица с тем же именем уже существует, то база данных пропускает команду CREATE TABLE .
Таблицу можно удалить при помощи инструкции DROP TABLE , а при помощи инструкции ALTER TABLE можно внести ограниченные изменения.
ALTER TABLE
Команда ALTER TABLE позволяет пользователю переименовать столбец или добавить новый столбец в существующую таблицу. Столбец невозможно удалить из таблицы.
Sql-statement::= ALTER TABLE table-name alteration alteration::= RENAME TO new-table-name alteration::= ADD column-def
Синтаксис RENAME TO используется для переименования таблицы, определенной table-name , в new-table-name . Эту команда нельзя использовать для переноса таблицы между присоединенными базами данных — она служит только для переименования таблицы в одной базе данных.
Если переименовываемая таблица содержит триггеры или индексы, они остаются прикрепленными к таблице после переименования. При этом, если имеются любые определения представлений или инструкции, выполняемые триггерами, которые ссылаются на переименовываемую таблицу, они не изменяются автоматически для использования нового имени таблицы. Если с переименованной таблицей связаны представления или триггеры, триггеры или определения представлений необходимо вручную удалить и создать повторно с новым именем таблицы.
Синтаксис ADD используется для добавления нового столбца в существующую таблицу. Новый столбец всегда добавляется в конец списка существующих столбцов. Предложение column-def может принимать любые формы, допустимые в инструкции CREATE TABLE , со следующими ограничениями:
- Столбец не может иметь ограничения PRIMARY KEY или UNIQUE .
- Столбец не может иметь значения по умолчанию CURRENT_TIME , CURRENT_DATE или CURRENT_TIMESTAMP .
- Если указано ограничение NOT NULL , столбец должен иметь значение по умолчанию, отличное от NULL .
Объем данных в таблице не влияет на время выполнения инструкции ALTER TABLE .
DROP TABLE
Инструкция DROP TABLE удаляет таблицу, добавленную с помощью инструкции CREATE TABLE . Таблица с указанным table-name — это удаленная таблица. Она полностью удаляется из базы данных и с диска. Восстановить таблицу невозможно. Все связанные с таблицей индексы также удаляются.
Sql-statement::= DROP TABLE table-name
По умолчанию инструкция DROP TABLE не уменьшает размер файла базы данных. Пустой пространство в базе данных сохраняется и используется в последующих операциях INSERT . Для удаления пустого пространства в базе данных служит метод SQLConnection.clean() . Если параметру autoClean присвоено значение true при первоначальном создании базы данных, пространство высвобождается автоматически.
Необязательное предложение IF EXISTS подавляет ошибку, которая обычно возникает, если таблица не существует.
CREATE INDEX
Команда CREATE INDEX состоит из ключевых слов CREATE INDEX с именем нового индекса, ключевым словом ON , именем ранее созданной таблицы, подлежащей индексации, и параметризованным списком имен столбцов в таблице, чьи значения используются для ключа индекса.
Sql-statement::= CREATE INDEX index-name ON table-name (column-name [, column-name]*) column-name::= name
За каждым именем столбца должно следовать ключевое слово ASC или DESC для указания порядка сортировки, но обозначение порядка сортировки пропускается средой выполнения. Сортировка всегда выполняется по возрастанию.
Предложение COLLATE после каждого имени столбца определяет параметры сортировки, применяемые к текстовым значениям в этом столбце. Параметры сортировки по умолчанию — это параметры сортировки, определенные для такого столбца в инструкции CREATE TABLE . Если параметры сортировки не заданы, используются параметры сортировки BINARY . Определение предложения COLLATE и функций сортировки см. в разделе .
Не существует произвольных пределов на число индексов, которые можно присоединить к отдельной таблице. Также отсутствуют пределы на число столбцов в индексе.
DROP INDEX
Инструкция удаления индекса позволяет удалить индекс, добавленный с помощью инструкции CREATE INDEX . Указанный индекс полностью удаляется из файла базы данных. Единственным способом восстановления индекса является повторный ввод команды CREATE INDEX .
Sql-statement::= DROP INDEX index-name
По умолчанию инструкция DROP INDEX не уменьшает размер файла базы данных. Пустой пространство в базе данных сохраняется и используется в последующих операциях INSERT . Для удаления пустого пространства в базе данных служит метод SQLConnection.clean() . Если параметру autoClean присвоено значение true при первоначальном создании базы данных, пространство высвобождается автоматически.
CREATE VIEW
Команда CREATE VIEW служит для назначения имени предопределенной инструкции SELECT . Затем это имя можно использовать в предложении FROM другой инструкции SELECT вместо имени таблицы. Представления, как правило, служат для упрощения запросов путем объединения сложного (или часто используемого) набора данных в структуру, которую можно использовать в других операциях.
Sql-statement::= CREATE VIEW view-name AS select-statement
Если ключевое слово TEMP или TEMPORARY стоит между CREATE и VIEW , то создаваемое представление будет видимым только экземпляру SQLConnection, который открыл базу данных, и будет удалено при закрытии базы данных.
Если указан , то представление создается в именованной базе данных (базе данных, подключенной к экземпляру SQLConnection при помощи метода attach() с указанным аргументом name). Ошибочным будет указание и ключевого слова TEMP , если не является temp . Если имя базы данных не указано, а ключевое слово TEMP присутствует, то представление создается в основной базе данных (базе данных, подключенной к экземпляру SQLConnection при помощи метода open() или openAsync()).
Представления доступны только для чтения. Инструкцию DELETE , INSERT или UPDATE нельзя использовать с представлением, если не определен, по меньшей мере, один триггер связанного типа (INSTEAD OF DELETE , INSTEAD OF INSERT , INSTEAD OF UPDATE). Дополнительные сведения о создании триггера для представления см. в разделе .
Для удаления представления из базы данных служит инструкция DROP VIEW .
DROP VIEW
Инструкция DROP VIEW удаляет представление, созданное с помощью инструкции CREATE VIEW .
Sql-statement::= DROP VIEW view-name
Указанный view-name является именем удаляемого представления. Представление удаляется из базы данных, но данные в базовых таблицах не изменяются.
CREATE TRIGGER
Инструкция создания триггера служит для добавления триггеров к схеме базы данных. Триггер — это операция базы данных (trigger-action), выполняемая автоматически при возникновении заданного события базы данных (database-event).
Sql-statement::= CREATE TRIGGER trigger-name database-event ON table-name trigger-action sql-statement::= CREATE TRIGGER trigger-name INSTEAD OF database-event ON view-name trigger-action database-event::= DELETE | INSERT | UPDATE | UPDATE OF column-list trigger-action::= BEGIN trigger-step ; [ trigger-step ; ]* END trigger-step::= update-statement | insert-statement | delete-statement | select-statement column-list::= column-name [, column-name]*
Триггер задается для запуска при возникновении события DELETE , INSERT или UPDATE определенной таблицы базы данных, или при обновлении одного или нескольких заданных столбцов таблицы при помощи инструкции UPDATE . Триггеры являются постоянными, если не используется ключевое слово TEMP или TEMPORARY . В таком случае триггер удаляется при закрытии подключения к основной базе данных экземпляра SQLConnection. Если время не указано (BEFORE или AFTER), триггер по умолчанию имеет значение BEFORE .
Поддерживаются только триггеры FOR EACH ROW , поэтому текст FOR EACH ROW является необязательным. С триггером FOR EACH ROW инструкции trigger-step выполняются для каждой вставляемой, обновляемой или удаляемой при помощи инструкции строки базы данных, вызывая запуск триггера, если выражение предложения WHEN получает значение true .
При указании предложения WHEN , инструкции SQL, указанные в качестве шагов триггера, выполняются только для строк, для которых предложение WHEN является истинным (true). Если предложение WHEN не указано, инструкции SQL выполняются для всех строк.
В теле триггера (предложение trigger-action) значения до изменения и после изменения затронутой таблицы доступны при помощи специальных имен таблиц OLD и NEW . Структура таблиц OLD и NEW соответствует структуре таблицы, для которой создается триггер. Таблица OLD содержит любые строки, измененные или удаленные инструкцией триггера, и их состояние до операций инструкции триггера. Таблица NEW содержит любые строки, измененные или созданные инструкцией триггера, и их состояние после операций инструкции триггера. Как предложение WHEN , так и инструкции trigger-step могут обращаться к значениям из вставляемых, удаляемых или обновляемых строк посредством ссылок вида NEW.column-name и OLD.column-name , где column-name — имя столбца из таблицы, с которой связан триггер. Доступность ссылок на таблицы OLD и NEW зависит от типа database-event , обрабатываемого триггером:
Указанное время (BEFORE , AFTER или INSTEAD OF) определяет время выполнения инструкций trigger-step относительно вставке, изменению или удалению связанной строки. Предложение ON CONFLICT может быть указано в составе инструкции UPDATE или INSERT в trigger-step . При этом если предложение ON CONFLICT указано в составе инструкции, вызывающей запуск триггера, то вместо этого используется политика разрешения конфликтов.
Помимо триггеров таблиц, триггер INSTEAD OF можно создать для представления. Если для представления определен один или несколько триггеров INSTEAD OF INSERT , INSTEAD OF DELETE или INSTEAD OF UPDATE , выполнение связанного типа инструкции для представления не будет считаться ошибкой (INSERT , DELETE и UPDATE). В этом случае выполнение INSERT , DELETE или UPDATE для представления приводит к запуску связанных триггеров. Так как триггер является триггером INSTEAD OF , таблицы в основе представления не изменяются инструкцией, запускающей триггер. При этом триггеры можно использовать для выполнения операций изменения с базовыми таблицами.
При создании триггера в таблице со столбцом INTEGER PRIMARY KEY важно помнить об одном. Если триггер BEFORE изменяет столбец INTEGER PRIMARY KEY строки, которая подлежит обновлению инструкцией, вызывающей запуск триггера, обновление не происходит. Выходом может быть создание таблицы со столбцом PRIMARY KEY вместо столбца INTEGER PRIMARY KEY .
Триггер можно удалить с помощью инструкции DROP TRIGGER . При удалении таблицы или представления, все триггеры, связанные с такой таблицей или представлением, также автоматически удаляются.
Функция RAISE()
В инструкции trigger-step триггера можно использовать специальную функцию SQL RAISE() . Эта функция имеет следующий синтаксис:
Raise-function::= RAISE (ABORT, error-message) | RAISE (FAIL, error-message) | RAISE (ROLLBACK, error-message) | RAISE (IGNORE)
Одна из трех форм вызывается во время выполнения триггера, выполняется указанное действие обработки ON CONFLICT (ABORT , FAIL или ROLLBACK) и выполнение текущей инструкции прекращается. ROLLBACK считается ошибкой выполнения инструкции, поэтому экземпляр SQLStatement, чей метод execute() выполнялся, выдает событие error (SQLErrorEvent.ERROR). Объект SQLError в свойстве error выданного события объекта имеет свойство details со значением error-message , заданным в функции RAISE() .
При вызове RAISE(IGNORE) остальная часть текущего триггера, инструкция, вызвавшая выполнение триггера и любые последующие триггеры, которые должны были бы быть выполнены, пропускаются. Откат изменений базы данных не выполняется. Если инструкция, вызвавшая выполнение триггера сама является частью триггера, эта программа-триггер возобновляет выполнение с начала следующего шага. Дополнительные сведения об алгоритмах разрешения конфликтов см. в разделе .
DROP TRIGGER
Инструкция DROP TRIGGER удаляет триггер, созданный с помощью инструкции CREATE TRIGGER .
Sql-statement::= DROP TRIGGER trigger-name
Триггер удаляется из базы данных. Следует помнить, что триггеры автоматически удаляются при удалении связанной с ними таблицы.
Специальные инструкции и предложения
В этом разделе описано несколько предложений, представляющих собой расширения SQL, обеспечиваемые средой времени выполнения, а также два элемента языка, которые можно использовать во многих инструкциях, комментариях и выражениях. В этом разделе рассматриваются следующие элементы:
COLLATE
Предложение COLLATE используется в инструкциях SELECT , CREATE TABLE и CREATE INDEX для указания алгоритма сравнения, используемого при сравнении или сортировке значений.
Sql-statement::= COLLATE collation-name collation-name::= BINARY | NOCASE
Для столбцов типом сортировки по умолчанию является BINARY . При использовании сортировки BINARY со значениями класса хранения TEXT , двоичная сортировка выполняется путем сравнения байтов в памяти, представляющих значение, независимо от кодировки текста.
Параметры сортировки NOCASE применяются только к значениями класса хранения TEXT . При использовании сортировка NOCASE выполняет независимое от регистра сравнение.
Параметры сортировки не используются для классов хранения типа NULL , BLOB , INTEGER или REAL .
Чтобы использовать тип сортировки, отличный от BINARY со столбцом, в составе определения столбца в инструкции CREATE TABLE необходимо указать предложение COLLATE . Каждый раз при сравнении двух значений TEXT , параметры сортировки используются для определения результатов сравнения по следующим правилам:
- В случае с операторами двоичного сравнения (= , < , > , <= и >=) если один из операндов является столбцом, то тип сортировки столбца по умолчанию определяет параметры сортировки, используемые для сравнения. Если оба операнда являются столбцами, то тип сортировки для левого операнда определяет используемые параметры сортировки. Если ни один из операндов не является столбцом, то используют параметры сортировки BINARY .
- Оператор BETWEEN...AND эквивалентен использованию двух выражений с операторами >= и <= . Например, выражение x BETWEEN y AND z эквивалентно x >= y AND x <= z . Таким образом, оператор BETWEEN...AND следует описанному правилу для определения параметров сортировки.
- Оператор IN по своему поведению напоминает оператор = для целей определения используемых параметров сортировки. Например, параметры сортировки, используемые для выражения x IN (y, z) , представляют тип сортировки по умолчанию для x , если x является столбцом. В противном случае, применяется сортировка BINARY .
- Предложению ORDER BY , являющемуся частью инструкции SELECT , можно явно присвоить параметры сортировки, используемые для операции сортировки. В этом случае всегда используются явные параметры сортировки. И наоборот, если выражение, отсортированное предложением ORDER BY , является столбцом, то тип сортировки по умолчанию для столбца используется для определения порядка сортировки. Если выражение не является столбцом, то используют параметры сортировки BINARY .
EXPLAIN
Модификатор команды EXPLAIN является нестандартным расширением SQL.
Sql-statement::= EXPLAIN sql-statement
Если ключевое слово EXPLAIN указать после любой другой инструкции SQL, то вместо фактического выполнения команды результат выдаст последовательность инструкций виртуальной машины, которые бы использовались для выполнения команды, если бы ключевое слово EXPLAIN отсутствовало. Функция EXPLAIN — это дополнительная возможность, позволяющая разработчикам изменять текст инструкции SQL в попытке оптимизировать производительность или отладить инструкцию, которая работает неправильно.
ON CONFLICT (алгоритмы конфликтов)
Предложение ON CONFLICT не является отдельной командой SQL. Это нестандартное предложение, которое может использоваться во многих других командах SQL.
Conflict-clause::= ON CONFLICT conflict-algorithm conflict-clause::= OR conflict-algorithm conflict-algorithm::= ROLLBACK | ABORT | FAIL | IGNORE | REPLACE
Первая форма предложения ON CONFLICT с ключевым словом ON CONFLICT используется в инструкции CREATE TABLE . Для инструкции INSERT или UPDATE используется вторая форма, где ON CONFLICT заменяется OR для придания более естественного вида синтаксису. Например, вместо INSERT ON CONFLICT IGNORE используется инструкция INSERT OR IGNORE . Несмотря на разные ключевые слова, значение предложения не меняется в обеих формах.
Предложение ON CONFLICT задает алгоритм, используемый для разрешения конфликтов ограничений. Существует пять алгоритмов: ROLLBACK , ABORT , FAIL , IGNORE и REPLACE . Алгоритм по умолчанию — ABORT . Далее приводится описание пяти алгоритмов конфликтов:
- ROLLBACK . При возникновении нарушения ограничения незамедлительно происходит ROLLBACK , что завершает текущую транзакцию. Выполнение команды прекращается и экземпляр SQLStatement выдает событие error . Если активной транзакции нет (кроме подразумеваемой транзакции, создаваемой для каждой команды), то этот алгоритм работает так же, как ABORT .
- ABORT . При возникновении нарушения ограничения, команда аннулирует все предыдущие изменения, которые могли быть внесены, а экземпляр SQLStatement выдает событие error . ROLLBACK не выполняется, поэтому изменения, внесенные предыдущими командами в транзакции, сохраняются. ABORT — это поведение по умолчанию.
- FAIL . При возникновении нарушения ограничения выполнение команды прекращается и SQLStatement выдает событие error . При этом любые изменения в базе данных, внесенные инструкцией до возникновения нарушения ограничения, сохраняются и не аннулируются. Например, если инструкция UPDATE сталкивается с нарушением ограничения на 100-ой строке, которую она пытается обновить, то сохраняются только первые 99 строк и изменения 100-ой строки и последующих строк не происходят.
- IGNORE . При возникновении нарушения ограничения строка с нарушением ограничения не вставляется или не изменяется. Несмотря на пропуск этой строки, команда продолжает выполняться в обычном режиме. Другие строки до и после строки с нарушением ограничения вставляются и обновляются далее как обычно. Ошибка не возвращается.
- REPLACE . При возникновении нарушения ограничения UNIQUE , ранее существующие строки, вызывающие нарушение ограничения, удаляются перед вставкой или обновлением текущей строки. Следовательно, вставки или обновление происходит всегда, и команда продолжает выполняться в обычном режиме. Ошибка не возвращается. При возникновении нарушения ограничения NOT NULL значение NULL заменяется значением по умолчанию для этого столбца. Если столбец не имеет значения по умолчанию, используется алгоритм ABORT . Если возникает нарушение ограничения CHECK , используется алгоритм IGNORE . Когда строки удаляются этой стратегией разрешения конфликтов для удовлетворения ограничения, удаление триггеров в этих строках не вызывается.
Алгоритм, заданный в предложении OR инструкции INSERT или UPDATE , переопределяет любой алгоритм, указанный в инструкции CREATE TABLE . Если в инструкции CREATE TABLE или выполняющей инструкции INSERT или UPDATE алгоритм не указан, используется алгоритм ABORT .
REINDEX
Команда REINDEX служит для удаления и повторного создания одного или нескольких индексов. Эта команда полезна, когда определение параметров сортировки было изменено.
Sql-statement::= REINDEX collation-name sql-statement::= REINDEX (table-name | index-name)
В первой форме все индексы в подключенных базах данных, использующих именованные параметры сортировки, создаются повторно. Во второй форме при указании table-name происходит повторное построение всех индексов, связанных с таблицей. Если указан index-name , то удаляется, а затем повторно создается только заданный индекс.
Комментарии
Комментарии не являются командами SQL, но могут содержаться в запросах SQL. Средой времени выполнения они воспринимаются как интервалы. Они могут начинаться в любом месте, где обнаружен интервал, в том числе внутри выражений, занимающих несколько строк.
Comment::= single-line-comment | block-comment single-line-comment::= -- single-line block-comment::= /* multiple-lines or block [*/]
Однострочный комментарий помечается двумя дефисами. Однострочный комментарий может простираться только до конца текущей строки.
Блоки комментариев могут распространяться на любое число строк или встраиваться в одну строку. Если завершающий разделитель отсутствует, блок комментариев простирается до конца ввода. Эта ситуация не считается ошибкой. Новая инструкция SQL может начинаться на строке после конца блока комментариев. Блоки комментариев можно встраивать в любое место, где имеется интервал, в том числе внутри выражений и в середине других инструкций SQL. Блоки комментариев не бывают вложенными. Однострочные комментарии внутри блока комментариев пропускаются.
Выражения
Выражения представляют собой подкоманды внутри других блоков SQL. Ниже описан допустимый синтаксис выражения в инструкции SQL:
Expr::= expr binary-op expr | expr like-op expr | unary-op expr | (expr) | column-name | table-name.column-name | database-name.table-name.column-name | literal-value | parameter | function-name(expr-list | *) | expr ISNULL | expr NOTNULL | expr BETWEEN expr AND expr | expr IN (value-list) | expr IN (select-statement) | expr IN table-name | (select-statement) | CASE (WHEN expr THEN expr)+ END | CAST (expr AS type) | expr COLLATE collation-name like-op::= LIKE | GLOB binary-op::= см. unary-op::= см. parameter::= :param-name | @param-name | ? value-list::= literal-value [, literal-value]* literal-value::= literal-string | literal-number | literal-boolean | literal-blob | literal-null literal-string::= "строковое значение" literal-number::= integer | number literal-boolean::= true | false literal-blob::= X"строка шестнадцатиричных данных" literal-null::= NULL
Выражение — это любое сочетание значений и операторов, которые могут приводить к одному значению. Выражения можно разделить на два основных типа согласно тому, приводят ли они к логическому (true или false) или не логическому значению.
В некоторых ситуациях (в предложении WHERE, предложении HAVING, выражении ON в предложении JOIN и выражении CHECK) выражение должно приводить к логическому значению. Этому условию удовлетворяют следующие типы выражений:
Значения литерала
Числовые значения литерала записываются в виде целого числа или числа с плавающей запятой. Поддерживается экспоненциальное представление. Символ. (точка) всегда используется в качестве десятичной точки.
Строковый литерал обозначается заключением строки в одинарные кавычки " . Чтобы включить одинарные кавычки в строку, добавьте две одинарные кавычки в строку, например: "" .
Логический литерал обозначается значением true или false . Логические значения литерала используются с логическим типом данных столбца.
Литерал BLOB представляет собой строковый литерал с шестнадцатиричными данными и символом x или X в начале, например: X"53514697465" .
Значением литерала может также быть маркер NULL .
Имя столбца
Именем столбца может быть любое имя, определенное в инструкции CREATE TABLE , или один из следующих специальных идентификаторов: ROWID , OID или _ROWID_ . Все эти специальные идентификаторы описывают уникальный произвольный ключ целых значений ("ключ строки"), связанный с каждой строкой каждой таблицы. Специальные идентификаторы относятся к ключу строки, только если инструкция CREATE TABLE не определяет существующий столбец с тем же именем. Ключи строк действуют так же как столбцы только для чтения. Ключ строки можно использовать там, где можно использовать обычный столбец, однако значение ключа строки нельзя изменять в инструкции UPDATE или INSERT . Инструкция SELECT * FROM table не содержит ключ строки в своем результирующем наборе.
Инструкция SELECT
Инструкция SELECT может присутствовать в выражении в качестве правого операнда оператора IN , скалярного количества (отдельное значение результата) или операнда оператора EXISTS . При использовании в качестве скалярного количества или операнда оператора IN , в результате SELECT может быть только один столбец. Допускается составная инструкция SELECT (соединенная ключевыми словами UNION или EXCEPT). С оператором EXISTS столбцы в результирующем наборе SELECT пропускаются, и выражение возвращает TRUE , если существует одна или несколько строк, и FALSE , если результирующий набор пуст. Если никакие условия в выражении SELECT не ссылаются на значение в содержащем запросе, выражение вычисляется один раз перед любой другой обработкой и результат используется повторно по мере необходимости. Если в выражении SELECT не содержатся переменные из внешнего запроса, известном как связанный вложенный запрос, SELECT вычисляется повторно каждый раз, когда требуется.
Если SELECT является правым операндом оператора IN , оператор IN возвращает TRUE , если результат левого операнда равен любому из значений в результирующем наборе инструкции SELECT . Оператору IN может предшествовать ключевое слово NOT для изменения значения теста.
Если SELECT содержится внутри выражения и не является правым операндом оператора IN , первая строка результата SELECT становится значением, используемым в выражении. Если SELECT выдает более одной строки результатов, все строки после первой пропускаются. Если SELECT не выдает строк, значением SELECT будет NULL .
Выражение CAST
Дополнительные элементы выражений
В следующих разделах описаны дополнительные элементы SQL, которые можно использовать в выражениях:
Встроенные функции
Встроенные функции подразделяются на три основные категории:
Помимо этих функций существует специальная функция RAISE() , которая используется для предоставления уведомления об ошибке в выполнении триггера. Эту функцию можно использовать только внутри тела инструкции CREATE TRIGGER . Сведения о функции RAISE() см. в разделе .
Как и все ключевые слова в SQL, имена функций не зависят от регистра.
Статические функции
Статические функции выполняют операции со значениями из нескольких строк. Эти функции в основном используются в инструкциях SELECT вместе с предложением GROUP BY .
| AVG(X) | Возвращает среднее значение всех не NULL X в группе. Строковые и BLOB-значения, не похожие на числа, рассматриваются как 0. Результатом AVG() всегда является значение с плавающей запятой, даже если все входные значения — целые числа. |
| Первая форма возвращает число раз, которое X не является NULL в группе. Вторая форма (с аргументом *) возвращает общее число строк в группе. | |
| MAX(X) | Возвращает максимальное значение всех значений в группе. Для определения максимального значения используется обычный порядок сортировки. |
| MIN(X) | Возвращает минимальное не NULL значение всех значений в группе. Для определения минимального значения используется обычный порядок сортировки. Если все значения в группе равны NULL , возвращается NULL . |
| Возвращает сумму чисел всех не NULL значений в группе. Если все значения равны NULL , то SUM() возвращает NULL , а TOTAL() возвращает 0.0 . Результатом TOTAL() всегда является значение с плавающей запятой. Результатом SUM() является целочисленное значение, если все не NULL входные значения являются целыми числами. Если какое-либо входное значение для SUM() не является целым числом и не NULL , SUM() возвращает значение с плавающей запятой. Это значение может быть приблизительным числом верной суммы. |
В любой из предыдущих статических функций, принимающих отдельный аргумент, перед этим аргументом можно использовать ключевое слово DISTINCT . В таком случае повторяющиеся элементы фильтруются перед передачей в статическую функцию. Например, вызов функции COUNT(DISTINCT x) возвращает число неодинаковых значений столбца X, а не общее число не NULL значений в столбце x .
Скалярные функции
Скалярные функции выполняют операции со значениями по одной строке за раз. Ниже приводится список этих функций:
| ABS(X) | Возвращает абсолютное значение аргумента X . |
| COALESCE(X, Y, ...) | Возвращает копию первого не NULL аргумента. Если все аргументы равны NULL , возвращается NULL . Требуется, по меньшей мере, два аргумента. |
| GLOB(X, Y) | Эта функция служит для реализации синтаксиса X GLOB Y . |
| IFNULL(X, Y) | Возвращает копию первого не NULL аргумента. Если оба аргумента равны NULL , возвращается NULL . Эта функция действует так же, как COALESCE() . |
| HEX(X) | Аргумент рассматривается как значение типа хранения BLOB. Результатом является шестнадцатиричное отображение содержимого этого значения. |
| LAST_INSERT_ROWID() | Возвращает идентификатор (созданный первичный ключ) последней строки, вставленной в базу данных через текущий экземпляр SQLConnection. Это значение совпадает со значением, которое возвращает свойство SQLConnection.lastInsertRowID . |
| LENGTH(X) | Возвращает длину строки X в символах. |
| LIKE(X, Y [, Z]) | Эта функция служит для реализации синтаксиса SQL X LIKE Y . Если присутствует необязательное предложение ESCAPE , функция вызывается с тремя аргументами. В противном случае она вызывается только с двумя аргументами. |
| LOWER(X) | Возвращает копию строки X с преобразованием всех символов в строчные. |
| Возвращает строку с удаленными пробелами слева от X . Если указан аргумент Y , функция удаляет любые символы в Y слева от X . | |
| MAX(X, Y, ...) | Возвращает аргумент с максимальным значением. Аргументы могут представлять строки, добавленные к числам. Максимальное значение определяется заданным порядком сортировки. Следует отметить, что функция MAX() является простой, когда имеет 2 или более аргументов, но с одним аргументом является статической функцией. |
| MIN(X, Y, ...) | Возвращает аргумент с минимальным значением. Аргументы могут представлять строки, добавленные к числам. Минимальное значение определяется заданным порядком сортировки. Следует отметить, что функция MIN() является простой, когда имеет 2 или более аргументов, но с одним аргументом является статической функцией. |
| NULLIF(X, Y) | Возвращает первый аргумент, если аргументы отличаются; в противном случае возвращает NULL . |
| QUOTE(X) | Эта подпрограмма возвращает строку, которая представляет значение своего аргумента, подходящее для вставки в другую инструкцию SQL. Строки заключаются в одинарные кавычки с escape-символами во внутренних кавычках в зависимости от необходимости. Классы хранения BLOB кодируются в шестнадцатиричные литералы. Эту функция полезна при написании триггеров для реализации функций отмены или повтора действий. |
| RANDOM(*) | Возвращает псевдослучайное целое число из интервала -9223372036854775808 — 9223372036854775807. Это случайное значение не является стойким к шифрованию. |
| RANDOMBLOB(N) | Возвращает N -байтов объекта BLOB с псевдослучайными байтами. N должно быть положительным целым числом. Это случайное значение не является стойким к шифрованию. Если значение N является отрицательным, возвращается один байт. |
| Округляет число X до Y знаков справа от десятичной точки. Если аргумент Y опущен, используется 0. | |
| Возвращает строку с удаленными пробелами слева от X . Если указан аргумент Y , функция удаляет любые символы в Y справа от X . | |
| SUBSTR(X, Y, Z) | Возвращает подстроку входящей строки X , начинающейся с Y символа длиной Z символов. Крайний левый символ X представляет положение индекса 1. Если Y является отрицательным, первый символ подстроки находится путем подсчета справа, а не слева. |
| Возвращает строку с удаленными пробелами слева и справа от X . Если указан аргумент Y , функция удаляет любые символы в Y слева и справа от X . | |
| TYPEOF(X) | Возвращает тип выражения X . Возможные возвращаемые значения: "null", "integer", "real", "text" и "blob". Дополнительные сведения о типах данных см. в разделе . |
| UPPER(X) | Возвращает копию входящей строки X с преобразованием всех символов в прописные. |
| ZEROBLOB(N) | Возвращает BLOB с N байтами 0x00. |
Функции форматирования даты и времени
Функции форматирования даты и времени представляют собой группу скалярных функций, используемых для создания форматированных данных даты и времени. Следует отметить, что эти функции работают со строковыми и числовыми значениями и возвращают их. Эти функции не предназначены для использования с типом данных DATE. Если их использовать с данными в столбце, объявленный тип данных которого — DATE, их поведение будет не таким, как требуется.
| DATE(T, ...) | Функция DATE() возвращает строку, содержащую дату в следующем формате: ГГГГ-ММ-ДД. Первый параметр (T) задает строку времени формата, расположенного в разделе . После строки времени можно указать любое число модификаторов. Модификаторы расположены в разделе . |
| TIME(T, ...) | Функция TIME() возвращает строку, содержащую время в формате ЧЧ:ММ:СС. Первый параметр (T) задает строку времени формата, расположенного в разделе . После строки времени можно указать любое число модификаторов. Модификаторы расположены в разделе . |
| DATETIME(T, ...) | Функция DATETIME() возвращает строку, содержащую дату и время в формате ГГГГ-ММ-ДД ЧЧ:ММ:СС. Первый параметр (T) задает строку времени формата, расположенного в разделе . После строки времени можно указать любое число модификаторов. Модификаторы расположены в разделе . |
| JULIANDAY(T, ...) | Функция JULIANDAY() возвращает число, обозначающее количество дней с полудня по Гринвичу 24 ноября 4714 до нашей эры и заданную дату. Первый параметр (T) задает строку времени формата, расположенного в разделе . После строки времени можно указать любое число модификаторов. Модификаторы расположены в разделе . |
| STRFTIME(F, T, ...) | Подпрограмма STRFTIME() возвращает дату по заданной строке формата в качестве первого аргумента F . Строка формата поддерживает следующие подстановочные знаки: Второй параметр (T) задает строку времени формата, расположенного в разделе . После строки времени можно указать любое число модификаторов. Модификаторы расположены в разделе . |
Форматы времени
Формат строки времени может быть любым из следующих:
| ГГГГ-ММ-ДД | 2007-06-15 |
| ГГГГ-ММ-ДД ЧЧ:ММ | 2007-06-15 07:30 |
| ГГГГ-ММ-ДД ЧЧ:ММ:СС | 2007-06-15 07:30:59 |
| ГГГГ-ММ-ДД ЧЧ:ММ:СС,ССС | 2007-06-15 07:30:59.152 |
| ГГГГ-ММ-ДДTЧЧ:ММ | 2007-06-15T07:30 |
| ГГГГ-ММ-ДДTЧЧ:ММ:СС | 2007-06-15T07:30:59 |
| ГГГГ-ММ-ДДTЧЧ:ММ:СС,ССС | 2007-06-15T07:30:59.152 |
| ЧЧ:ММ | 07:30 (дата: 2000-01-01) |
| ЧЧ:ММ:СС | 07:30:59 (дата: 2000-01-01) |
| ЧЧ:ММ:СС,ССС | 07:30:59:152 (дата: 2000-01-01) |
| now | Текущая дата и время в формате UTC. |
| ДДДД.ДДДД | День по юлианскому календарю в виде числа с плавающей запятой |
Символ T в этих форматах представляет буквенный символ "T", разделяющий дату и время. Форматы, включающие только время, предполагают дату 2001-01-01.
Модификаторы
После строки времени может следовать ноль или несколько модификаторов, изменяющих дату или толкование даты. Доступны следующие модификаторы:
| NNN дней | Число дней, прибавляемое к времени. |
| NNN часов | Число часов, прибавляемое к времени. |
| NNN минут | Число минут, прибавляемое к времени. |
| NNN,NNNN секунд | Число секунд или миллисекунд, прибавляемое к времени. |
| NNN месяцев | Число месяцев, прибавляемое к времени. |
| NNN лет | Число лет, прибавляемое к времени. |
| начало месяца | Смещение времени назад к началу месяца. |
| начало года | Смещение времени назад к началу года. |
| начало дня | Смещение времени назад к началу дня. |
| день недели N | Смещение времени вперед на указанный день недели. (0 = воскресенье, 1 = понедельник и т.д.) |
| localtime | Преобразование даты в местное время |
| utc | Преобразование даты в формат UTC |
Операторы
SQL поддерживает большое число операторов, включая распространенные операторы, существующие в большинстве языков программирования, а также несколько уникальных для SQL операторов.
Общие операторы
Следующие двоичные операторы допускаются в блоке SQL и перечислены в порядке приоритета — от высшего до низшего:
|| * / % + - << >> & | < <= > >= = == != <> IN AND ORПоддерживаются унарные префиксные операторы:
- ! ~ NOT
Оператор COLLATE можно представить как унарный постфиксный оператор. Оператор COLLATE имеет наивысший приоритет. Он всегда имеет более тесную привязку, чем префиксный унарный оператор или любой двоичный оператор.
Следует отметить, что существует две разновидности операторов равенства и неравенства. Равенство может иметь форму = или == . Оператор неравенства может иметь вид!= или <> .
Оператор || является строковым оператором сцепления — он соединяет две строки своих операндов.
Оператор % выдает остаток от деления правого операнда на левый операнд.
Результатом любого двоичного оператора является числовое значение, но это не относится к оператору сцепления || , который выдает строковый результат.
Операторы SQL
LIKE
Оператор LIKE выполняет сравнение шаблонов.
Expr::= (column-name | expr) LIKE pattern pattern::= "[ string | % | _ ]"
Операнд справа от оператора LIKE содержит шаблон, а левые операнд содержит строку для соответствия шаблону. Символ процента (%) в шаблоне представляет собой подстановочный знак и соответствует любой последовательности символов в строке (или отсутствию символов). Символ подчеркивания (_) в шаблоне соответствует любому отдельному символу в строке. Любой другой символ соответствует самому себе или эквивалентному символу нижнего/верхнего регистра, то есть совпадения определяются вне зависимости от регистра. (Примечание. Ядро СУБД понимает только верхний/нижний регистр 7-битных символов латиницы. Следовательно, оператор LIKE учитывает регистра для 8-битных символов iso8859 или символов UTF-8. Например, выражение "a" LIKE "A" является TRUE , но "æ" LIKE "Æ" — FALSE). Зависимость символов латинского алфавита от регистра можно изменить при помощи свойства SQLConnection.caseSensitiveLike .
Если присутствует необязательное предложение ESCAPE , то выражение после ключевого слова ESCAPE должно приводить к строке, состоящей из одного символа. Этот символ можно использовать в шаблоне LIKE для соответствия литеральному проценту или символам подчеркивания. Escape-знак после символа процента, символ подчеркивания или сам по себе соответствует символу литерального процента, символу подчеркивания или escape-знаку в строке, соответственно.
GLOB
Оператор GLOB похож на LIKE , но использует синтаксис глобализации Unix-файла для своих подстановочных знаков. В отличие от LIKE , GLOB зависит от регистра.
IN
Оператор IN вычисляет, равен ли его левый операнд одному из значений правого операнда (набору значений в скобках).
In-expr::= expr IN (value-list) | expr IN (select-statement) | expr IN table-name value-list::= literal-value [, literal-value]*
Правый операнд может быть набором литеральных значений, разделенных запятыми, или результатом инструкции SELECT . Описание и ограничения при использовании инструкций SELECT при использовании в качестве правого операнда оператора IN см. в описании инструкций SELECT .
BETWEEN...AND
Оператор BETWEEN...AND эквивалентен использованию двух выражений с операторами >= и <= . Например, выражение x BETWEEN y AND z эквивалентно x >= y AND x <= z .
NOT
Оператор NOT является оператором отрицания. Перед операторами GLOB , LIKE и IN можно поставить ключевое слово NOT для обращения значения теста (другими словами, для проверки того, что значение не соответствует указанному шаблону).
Параметры
Параметр указывает местозаполнитель в выражении для литерального значения, который заполняется во время выполнения путем присвоения значения ассоциативному массиву SQLStatement.parameters . Параметры могут иметь три формы:
Неподдерживаемые возможности SQL
- Ограничения FOREIGN KEY . Разбор ограничений FOREIGN KEY выполняется, но они не применяются.
- Триггеры . Триггеры FOR EACH STATEMENT не поддерживаются (все триггеры должны быть FOR EACH ROW). Триггеры INSTEAD OF не поддерживаются для таблиц (для представлений допускаются только триггеры INSTEAD OF). Рекурсивные триггеры (вызывающие самих себя) не поддерживаются.
- ALTER TABLE . Поддерживаются только варианты RENAME TABLE и ADD COLUMN команды ALTER TABLE . Другие типы операций ALTER TABLE , такие как DROP COLUMN , ALTER COLUMN , ADD CONSTRAINT и т.д., пропускаются.
- Вложенные транзакции . Допускается только одна активная транзакция.
- RIGHT и FULL OUTER JOIN . RIGHT OUTER JOIN или FULL OUTER JOIN не поддерживаются.
- Обновление VIEW . Представление доступно только для чтения. Для представления невозможно выполнить инструкцию DELETE , INSERT или UPDATE . Триггер INSTEAD OF , запускаемый при попытке выполнения DELETE , INSERT или UPDATE для представления, поддерживается и может использоваться для обновления вспомогательных таблиц в теле триггера.
- GRANT и REVOKE . База данных представляет собой простой файл на диске; единственные применяемые разрешения доступа — это обычные разрешения доступа к файлам в базовой операционной системе. Команды GRANT и REVOKE , обычно существующие в клиентских/серверных реляционных СУБД, не реализованы.
Следующие элементы SQL и возможности SQLite поддерживаются в некоторых реализациях SQLite, но не поддерживаются в Adobe AIR. Большая часть этих возможностей доступна через методы класса SQLConnection.
- Связанные с транзакциями элементы SQL (BEGIN , END , COMMIT , ROLLBACK) : Следующие функции доступны через связанными с транзакциями методы класса SQLConnection : SQLConnection.begin() , SQLConnection.commit() и SQLConnection.rollback() .
- ANALYZE SQLConnection.analyze() .
- ATTACH : Эта возможность доступна через метод SQLConnection.attach() .
- COPY
- CREATE VIRTUAL TABLE : Эта инструкция не поддерживается.
- DETACH : Эта возможность доступна через метод SQLConnection.detach() .
- PRAGMA : Эта инструкция не поддерживается.
- VACUUM : Эта возможность доступна через метод SQLConnection.compact() .
- Доступ к системной таблице отсутствует . Системные таблицы, в том числе sqlite_master и другие таблицы с префиксом "sqlite_" не доступны в инструкциях SQL. Среда времени выполнения включает API схемы, который представляет объектно-ориентированный способ доступа к данным схемы. Дополнительные сведения см. в описании метода SQLConnection.loadSchema() .
- Функция SQLITE_VERSION() : Функция sqlite_version() не доступна для использования в инструкциях SQL.
- Функции регулярных выражений (MATCH() и REGEX()) . Эти функции не доступны в инструкциях SQL.
Следующие возможности отличаются в различных реализациях SQLite и Adobe AIR:
- Индексированные параметры инструкций . Во многих реализациях индексированные параметры инструкций основаны на единице. Однако в Adobe AIR индексируемые параметры инструкций основаны на нуле (т.е., первому параметру присваивается индекс 0, второму параметру — индекс 1 и т.д.).
Дополнительные возможности SQL
Следующие типы сходства столбцов по умолчанию не поддерживаются в SQLite, но поддерживаются в Adobe AIR:
Следующие типы литеральных значений по умолчанию не поддерживаются в SQLite, но поддерживаются в Adobe AIR:
- Значение true . Представляет литеральное логическое значение true для работы со столбцами BOOLEAN.
- Значение false . Представляет литеральное логическое значение false для работы со столбцами BOOLEAN.
Поддерживаемые типы данных
В отличие от большинства баз данных SQL, ядро СУБД SQL Adobe AIR не требует, чтобы значения в столбцах таблицы имени определенный тип. Наоборот, среда времени выполнения для управления типами данных использует две концепции: классы хранения и сходство столбцов. В этом разделе описаны классы хранения и сходство столбцов, а также то, как различия типов данных разрешаются в различных условиях:
Классы хранения
Классы хранения представляют типы фактических данных, которые используются для хранения значений в базе данных. Доступны следующие классы хранения.
- NULL . Значение равно NULL .
- INTEGER . Значение является подписанным целым числом.
- REAL . Значение представляет числовое значение с плавающей запятой.
- TEXT . Значение является текстовой строкой (ограничивается 256 МБ).
- BLOB . Значение представляет большой двоичный объект (BLOB); другими словами, необработанные двоичные данные (ограничивается 256 МБ).
Перед выполнением инструкции SQL всем значениям, передаваемым в базу данных в виде литералов, встроенных в инструкцию SQL, или значениям, привязанным при помощи параметров к подготовленной инструкции SQL, назначается класс хранения.
Литералам, являющимся частью инструкции SQL, назначается класс хранения TEXT, если они заключены в одинарные или двойные кавычки, INTEGER, если литерал указан в виде числа без кавычек и без десятичной точки или экспонента, REAL, если литерал представляет собой число без кавычек с десятичной точкой или экспонент, и NULL, если значение равно NULL. Литералы с классом хранения BLOB обозначаются как X"ABCD" . Дополнительные сведения см. в разделе .
Значениям, подставляемым в виде параметров при помощи ассоциативного массива SQLStatement.parameters , назначается класс хранения, которые больше всего напоминает привязку к исходному типу данных. Например, значения int привязываются как класс хранения INTEGER, значениям Number назначается класс хранения REAL, значениям String — класс хранения TEXT, а объектам ByteArray — класс хранения BLOB.
Сходство столбцов
Сходство столбца является рекомендуемым типом для данных в таком столбце. Если в столбце сохраняется значение (посредством инструкции INSERT или UPDATE), среда выполнения пытается преобразовать тип данных этого значение к заданному сходству. Например, если значение Date (экземпляр Date ActionScript или JavaScript) вставляется в столбец со сходством TEXT, значение Date преобразовывается в представление String (эквивалентно вызову метода toString() объекта) перед сохранением в базе данных. Если значение не удается преобразовать к заданному сходству, возникает ошибка и операция не выполняется. При извлечении значения из базы данных при помощи инструкции SELECT , оно возвращается в виде экземпляра класса, соответствующего сходству, независимо от того, было ли оно преобразовано из другого типа в момент сохранения.
Если столбец принимает значения NULL, значение null ActionScript или JavaScript можно использовать как значение параметра для хранения NULL в столбце. При извлечении значения класса хранения NULL в инструкции SELECT оно всегда возвращается как значение null ActionScript или JavaScript независимо от сходства столбца. Если столбец принимает значения NULL, следует всегда проверять значения, извлекаемые из этого столбца, чтобы определить, равны ли они null , прежде чем выполнить попытку приведения значения к ненулевому типу (такому как Number или Boolean).
Каждому столбцу в базе данных назначается одно из следующих сходств типа:
- TEXT (или STRING)
- NUMERIC
- INTEGER
- REAL (или NUMBER)
- BOOLEAN
- XMLLIST
- OBJECT
TEXT (или STRING)
Столбец со сходством TEXT или STRING хранит все данные с использованием классов хранения NULL, TEXT или BLOB. Если в столбец вставляются данные со сходством TEXT, они преобразуются в текстовую форму перед сохранением.
NUMERIC
Столбец со сходством NUMERIC содержит значения с использованием классов хранения NULL, REAL или INTEGER. При вставке текстовых данных в столбец NUMERIC, перед сохранением выполняется попытка их преобразования в целое число или вещественное число. Если преобразование выполняется успешно, значение сохраняется с использованием класса хранения INTEGER или REAL (например, значение "10.05" преобразуется перед сохранением в класс хранения REAL). В случае невозможности выполнения преобразования происходит ошибка. Попытка преобразования значения NULL не выполняется. Значение, извлекаемое из столбца NUMERIC, возвращается как экземпляр самого специфического числового типа, в который подходит значение. Другими словами, если значение является положительным целым числом или 0, оно возвращается как экземпляр uint. Если оно представляет отрицательное целое число, то возвращается как экземпляр int. И, наконец, если в нем присутствует часть после запятой (не целое число), то оно возвращается как экземпляр Number.
INTEGER
По поведению столбец со сходством INTEGER напоминает столбец со сходством NUMERIC, но с одним исключением. Если сохраняемое значение является вещественным значением (таким как экземпляр Number) части после плавающей запятой, или если значение является текстом, которое можно преобразовать в вещественное значение с плавающей запятой, оно преобразуется в целое число и сохраняется с классом хранения INTEGER. При попытке сохранения вещественного значения с частью после плавающей запятой возникает ошибка.
REAL (или NUMBER)
Поведение столбца со сходством REAL или NUMBER аналогично поведению столбца со сходством NUMERIC, однако здесь целочисленные значения принудительно преобразуются в представление с плавающей запятой. Значение в столбце REAL всегда возвращается из базы данных в виде экземпляра Number.
BOOLEAN
Столбец со сходством BOOLEAN хранит истинные (true) или ложные (false) значения. Столбец BOOLEAN принимает значение, являющееся экземпляром Boolean ActionScript или JavaScript. При попытке кода сохранить значение String, String, длина которого превышает ноль, считается "true", а пустое значение String — "false". Если код попытается сохранить числовые данные, то любые ненулевые значения сохраняются как "true", а 0 как "false". При извлечении значения Boolean при помощи инструкции SELECT , оно возвращается как экземпляр Boolean. Не-NULL значения хранятся с использованием класса хранения INTEGER (0 для "false" и 1 для "true") и преобразуются в объекты Boolean во время извлечения данных.
DATE
Столбец со сходством DATE хранит значения даты и времени. Столбец DATE может принимать значения, являющиеся экземплярами Date ActionScript или JavaScript Date. При попытке сохранить значение String в столбец DATE, среда выполнения попытает преобразовать его в юлианскую дату. В случае невозможности выполнения преобразования происходит ошибка. Если код попытается сохранить значение Number, int или uint, то попытка проверки данных не выполняется и значение считается допустимым значением даты по юлианскому календарю. При извлечении значения DATE при помощи инструкции SELECT оно автоматически преобразуется в экземпляр Date. Значения DATE хранятся в виде значений юлианской даты с использованием класса хранения REAL, поэтому операторы сортировки и сравнения работают так, как требуется.
XML или XMLLIST
Столбец со сходством XML или XMLLIST содержит структуры XML. При попытке кода сохранить данные в столбце XML при помощи параметра SQLStatement среда выполнения попытается преобразовать и проверить значение с помощью функции ActionScript XML() или XMLList() . В случае невозможности преобразования значения в допустимый XML происходит ошибка. При попытке сохранения данных с использованием текстового значения SQL литерала (например, INSERT INTO (col1) VALUES (" Invalid XML (no closing tag) ") , разбор значения или проверка не выполняется, поскольку его форма считается правильной. Если сохранить недопустимое значение, то при извлечении оно возвращает пустой объект XML. Значение Data XML и XMLLIST Data сохраняется с использованием класса хранения TEXT или NULL.
OBJECT
Столбец со сходством OBJECT содержит сложные объекты ActionScript или JavaScript, включая экземпляры класса Object, а также экземпляры подклассов Object, такие как экземпляры Array и даже экземпляры пользовательских классов. Сериализация данных столбца OBJECT выполняется в формате AMF3 и они сохраняются с использованием класса хранения BLOB. При извлечении значения выполняется его десериализация из AMF3, и оно возвращается в виде экземпляра класса в том виде, в котором оно было сохранено. Следует отметить, что некоторые классы ActionScript, в особенности объекты представления, можно десериализовать как экземпляры их исходного типа данных. Прежде чем сохранять экземпляр пользовательского класса, необходимо зарегистрировать псевдоним класса при помощи метода flash.net.registerClassAlias() (или в Flex, добавив к объявлению класса метаданные ). Кроме того, перед извлечением таких данных необходимо зарегистрировать такой же псевдоним для класса. Любые данные, правильную десериализацию которых невозможно выполнить по той причине, что класс изначально не поддается десериализации или псевдоним класса отсутствует или несогласован, возвращается как анонимный объект (экземпляр класса Object) со свойствами и значениями, соответствующими изначально сохраненному экземпляру.
NONE
Столбец со сходством NONE не различает классы хранения. Попытка преобразования данных перед вставкой не выполняется.
Определение сходства
Сходство типа столбца определяется по объявленному типу столбца в инструкции CREATE TABLE . При определении типа действуют следующие правила.
- Если тип данных столбца содержит любые строки "CHAR", "CLOB", "STRI" или "TEXT", то столбец имеет сходство TEXT/STRING. Следует отметить, что тип VARCHAR содержит строку "CHAR" и ему назначается сходство TEXT.
- Если тип данных столбца содержит строки "BLOB" или тип данных не задан, то столбец имеет сходство NONE.
- Если тип данных столбца содержит строку "XMLL", то столбец имеет сходство XMLLIST.
- Если типом данных является строка "XML", то столбец имеет сходство XML.
- Если тип данных содержит строку "OBJE", то столбец имеет сходство OBJECT.
- Если тип данных содержит строку "BOOL", то столбец имеет сходство BOOLEAN.
- Если тип данных содержит строку "DATE", то столбец имеет сходство DATE.
- Если тип данных содержит строку "INT" (включая "UINT"), ему назначается сходство INTEGER.
- Если тип данных столбца содержит любые строки "REAL", "NUMB", "FLOA" или "DOUB", то столбец имеет сходство REAL/NUMBER.
- В противном случае, сходством будет NUMERIC.
- Если таблица создана с помощью инструкции CREATE TABLE t AS SELECT... , то тип данных для всех столбов не задается и им назначается сходство NONE.
Типы данных и операторы сравнения
Поддерживаются операторы двоичного сравнения = , < , <= , >= и!= , а также операция проверки заданного членства, оператор IN и оператор троичного сравнения BETWEEN . Подробные сведения об этих операторах см. в разделе .
Результат сравнения зависит от классов хранения двух сравниваемых значений. При сравнении двух значений действуют следующие правила.
- Значение с классом хранения NULL считается меньшим по отношению к любому другому значению (включая другое значение с классом хранения NULL).
- Значение INTEGER или REAL меньше любого значения TEXT или BLOB. При сравнении INTEGER или REAL с другим значением INTEGER или REAL выполняется сравнение чисел.
- Значение TEXT меньше значения BLOB. При сравнении двух значений TEXT выполняется двоичное сравнение.
- При сравнении двух значений BLOB результат всегда определяется по двоичному сравнению.
При выполнении двоичных сравнений классов хранения числа и текста, перед выполнением преобразования база данных пытается преобразовать значения (если требуется). При сравнении классов хранения числа и текста действуют следующие правила (Примечание. Термин выражение , используемый в описанных далее правилах, включает любое скалярное выражение SQL или литерал, отличный от значения столбца. Например, если X и Y.Z представляют имена столбцов, то +X и +Y.Z считаются выражениями):
- При сравнении значения столбца с результатом выражения сходство столбца применяется к результату выражения перед выполнением сравнения.
- Если при сравнении двух значений столбцов один столбец имеет сходство INTEGER, REAL или NUMERIC, а второй нет, то сходство NUMERIC применяется к любым значениям с классом хранения TEXT, извлеченным из не NUMERIC столбца.
- При сравнении результатов двух выражений преобразование не происходит. Результаты сравниваются "как есть". При сравнении строки с числом, последнее всегда меньше строки.
Троичный оператор BETWEEN всегда преобразуется в качестве эквивалента двоичному выражению. Например, a BETWEEN b AND c преобразуется к a >= b AND a <= c , даже если это означает, что разные сходства применяются к a при каждом сравнении, необходимом для вычисления выражения.
Выражения типа a IN (SELECT b ....) следуют трем правилам, перечисленным ранее для двоичного сравнения, то есть, аналогичны a = b . Например, если b — значение столбца, а a — выражение, то сходство b применяется к a перед любым сравнением. Выражение a IN (x, y, z) преобразуется к a = +x OR a = +y OR a = +z . Значения справа от оператора IN (в приведенном примере это значения x , y и z) считаются выражениями, даже если они являются значениями столбца. Если значение слева от оператора IN является столбцом, то используется сходство этого столбца. Если значение является выражением, то преобразование не происходит.
На порядок выполнения сравнений может также влиять предложение COLLATE . Дополнительные сведения см. в разделе .
Типы данных и математические операторы
По каждому из поддерживаемых математических операторов * , / , % , + и - применяется числовое сходство к каждому операнду перед вычислением выражения. Если какой-либо операнд не удается успешно преобразовать в класс хранения NUMERIC, результатом выражения будет NULL .
При использовании оператора сцепления || каждый операнд преобразуется в класс хранения TEXT перед вычислением выражения. Если какой-либо операнд не удается преобразовать в класс хранения NUMERIC, результатом выражения будет NULL . Невозможность преобразования значения может возникать в двух случаях: если значение операнда равно NULL , или есть это объект BLOB с классом хранения, отличным от TEXT.
Типы данных и сортировка
При сортировке значений при помощи предложения ORDER BY , на первое место ставится класс хранения NULL. Затем следуют значения INTEGER и REAL в числовом порядке, далее значения TEXT в двоичном порядке или в зависимости от заданной сортировки (BINARY или NOCASE). Завершают список значения BLOB в двоичном порядке. Перед сортировкой преобразования классов хранения не выполняется.
Типы данных и группировка
При группировке значений с помощью предложение GROUP BY , значения с различными классами хранения считаются разными. Исключением являются значения INTEGER и REAL, которые считаются равными, если их числа эквиваленты. Предложение GROUP BY не приводит к применению сходства к каким-либо значениям.
Типы данных и составные инструкции SELECT
Составные операторы SELECT — UNION , INTERSECT и EXCEPT — выполняют неявное сравнение значений. Перед выполнением этих сравнений к каждому значению может применяться сходство. Такое же сходство (если имеется) применяется ко всем значениям, которые могут быть возвращены в отдельном столбце результирующего набора составной инструкции SELECT . Применяемое сходство является сходством столбца, возвращаемого первым компонентом инструкции SELECT , имеющим значение столбца (а не какой-либо другой тип выражения) в этом положении. Если для заданного столбца составной инструкции SELECT ни один из компонентов инструкции SELECT не возвращает значение столбца, сходство не применяется к значениям из этого столбца перед их сравнением.
Обозначения, используемые в этом документе
В определениях выражений в этом документе использовались следующие обозначения.
- Регистр текста
- ВЕРХНИЙ РЕГИСТР — ключевые слова SQL литерала написаны в верхнем регистре
- нижний регистр — термины местозаполнителей или имена предложений записаны в нижнем регистре
- Символы определений
- ::= — обозначает определение предложения или выражения
- Группировка и альтернативные символы
- | — символ прямой черты используется между альтернативными параметрами и может читаться как "или"
- — элементы в квадратных скобках являются необязательными; в квадратные скобки может быть заключен один элемент или набор альтернативных элементов
- () — круглые скобки, в которых заключены альтернативные варианты (набор элементов, разделенных символами прямой черты) обозначает обязательную группу элементов, то есть, набор элементов, которые являются возможными значениями отдельного обязательного элемента
- Квантификаторы
- + — знак плюса после элемента в круглых скобках означает, что предшествующий ему элемент может встречаться 1 или более раз
- * — символ звездочки после элемента в квадратных скобках означает, что предшествующий ему (заключенный в скобки) элемент может встречаться 0 или более раз
- Символы литерала
- * — символ звездочки в имени столбца или между круглыми скобками после имени функции обозначает символ звездочки, а не квантификатора "0 или более"
- . — символ точки представляет точку литерала
- , — символ запятой представляет запятую литерала
- () — пара круглых скобок, в которые заключено отдельное предложение или элемент обозначает, что скобки являются обязательными символами скобок литерала.
- Другие символы. Если отсутствуют другие обозначения, остальные символы представляют соответствующие символы литерала
Для извлечения данных из базы данных используется язык SQL. SQL - это язык программирования, который очень напоминает английский, но предназначен для программ управления базами данных. SQL используется в каждом запросе в Access.
Понимание принципов работы SQL помогает создавать более точные запросы и упрощает исправление запросов, которые возвращают неправильные результаты.
Это статья из цикла статей о языке SQL для Access. В ней описаны основы использования SQL для выборки данных и приведены примеры синтаксиса SQL.
В этой статье
Что такое SQL?
SQL - это язык программирования, предназначенный для работы с наборами фактов и отношениями между ними. В программах управления реляционными базами данных, таких как Microsoft Office Access, язык SQL используется для работы с данными. В отличие от многих языков программирования, SQL удобочитаем и понятен даже новичкам. Как и многие языки программирования, SQL является международным стандартом, признанным такими комитетами по стандартизации, как ISO и ANSI .
На языке SQL описываются наборы данных, помогающие получать ответы на вопросы. При использовании SQL необходимо применять правильный синтаксис. Синтаксис - это набор правил, позволяющих правильно сочетать элементы языка. Синтаксис SQL основан на синтаксисе английского языка и имеет много общих элементов с синтаксисом языка Visual Basic для приложений (VBA).
Например, простая инструкция SQL, извлекающая список фамилий контактов с именем Mary, может выглядеть следующим образом:
SELECT Last_Name
FROM Contacts
WHERE First_Name = "Mary";
Примечание: Язык SQL используется не только для выполнения операций над данными, но еще и для создания и изменения структуры объектов базы данных, например таблиц. Та часть SQL, которая используется для создания и изменения объектов базы данных, называется языком описания данных DDL. Язык DDL не рассматривается в этой статье. Дополнительные сведения см. в статье Создание и изменение таблиц или индексов с помощью запроса определения данных .
Инструкции SELECT
Инструкция SELECT служит для описания набора данных на языке SQL. Она содержит полное описание набора данных, которые необходимо получить из базы данных, включая следующее:
таблицы, в которых содержатся данные;
связи между данными из разных источников;
поля или вычисления, на основе которых отбираются данные;
условия отбора, которым должны соответствовать данные, включаемые в результат запроса;
необходимость и способ сортировки.
Предложения SQL
Инструкция SQL состоит из нескольких частей, называемых предложениями. Каждое предложение в инструкции SQL имеет свое назначение. Некоторые предложения являются обязательными. В приведенной ниже таблице указаны предложения SQL, используемые чаще всего.
|
Предложение SQL |
Описание |
Обязательное |
|
Определяет поля, которые содержат нужные данные. |
||
|
Определяет таблицы, которые содержат поля, указанные в предложении SELECT. |
||
|
Определяет условия отбора полей, которым должны соответствовать все записи, включаемые в результаты. |
||
|
Определяет порядок сортировки результатов. |
||
|
В инструкции SQL, которая содержит статистические функции, определяет поля, для которых в предложении SELECT не вычисляется сводное значение. |
Только при наличии таких полей |
|
|
В инструкции SQL, которая содержит статистические функции, определяет условия, применяемые к полям, для которых в предложении SELECT вычисляется сводное значение. |
Термины SQL
Каждое предложение SQL состоит из терминов, которые можно сравнить с частями речи. В приведенной ниже таблице указаны типы терминов SQL.
|
Термин SQL |
Сопоставимая часть речи |
Определение |
Пример |
|
идентификатор |
существительное |
Имя, используемое для идентификации объекта базы данных, например имя поля. |
Клиенты.[НомерТелефона] |
|
оператор |
глагол или наречие |
Ключевое слово, которое представляет действие или изменяет его. |
|
|
константа |
существительное |
Значение, которое не изменяется, например число или NULL. |
|
|
выражение |
прилагательное |
Сочетание идентификаторов, операторов, констант и функций, предназначенное для вычисления одного значения. |
>= Товары.[Цена] |
Основные предложения SQL: SELECT, FROM и WHERE
Общий формат инструкций SQL:
SELECT field_1
FROM table_1
WHERE criterion_1
;
Примечания:
Access не учитывает разрывы строк в инструкции SQL. Несмотря на это, каждое предложение рекомендуется начинать с новой строки, чтобы инструкцию SQL было удобно читать как тому, кто ее написал, так и всем остальным.
Каждая инструкция SELECT заканчивается точкой с запятой (;). Точка с запятой может стоять как в конце последнего предложения, так и на отдельной строке в конце инструкции SQL.
Пример в Access
В приведенном ниже примере показано, как в Access может выглядеть инструкция SQL для простого запроса на выборку.
1. Предложение SELECT
2. Предложение FROM
3. Предложение WHERE
Разберем пример по предложениям, чтобы понять, как работает синтаксис SQL.
Предложение SELECT
SELECT , Company
Это предложение SELECT. Оно содержит оператор (SELECT), за которым следуют два идентификатора ("[Адрес электронной почты]" и "Компания").
Если идентификатор содержит пробелы или специальные знаки (например, "Адрес электронной почты"), он должен быть заключен в прямоугольные скобки.
В предложении SELECT не нужно указывать таблицы, в которых содержатся поля, и нельзя задать условия отбора, которым должны соответствовать данные, включаемые в результаты.
В инструкции SELECT предложение SELECT всегда стоит перед предложением FROM.
Предложение FROM
FROM Contacts
Это предложение FROM. Оно содержит оператор (FROM), за которым следует идентификатор (Контакты).
В предложении FROM не указываются поля для выборки.
Предложение WHERE
WHERE City="Seattle"
Это предложение WHERE. Оно содержит оператор (WHERE), за которым следует выражение (Город="Ростов").
С помощью предложений SELECT, FROM и WHERE можно выполнять множество действий. Дополнительные сведения об использовании этих предложений см. в следующих статьях:
Сортировка результатов: ORDER BY
Как и в Microsoft Excel, в Access можно сортировать результаты запроса в таблице. Используя предложение ORDER BY, вы также можете указать способ сортировки результатов при выполнении запроса. Если используется предложение ORDER BY, оно должно находиться в конце инструкции SQL.
Предложение ORDER BY содержит список полей, для которых нужно выполнить сортировку, в том же порядке, в котором будут применена сортировка.
Предположим, например, что результаты сначала нужно отсортировать по полю "Компания" в порядке убывания, а затем, если присутствуют записи с одинаковым значением поля "Компания", - отсортировать их по полю "Адрес электронной почты" в порядке возрастания. Предложение ORDER BY будет выглядеть следующим образом:
ORDER BY Company DESC,
Примечание: По умолчанию Access сортирует значения по возрастанию (от А до Я, от наименьшего к наибольшему). Чтобы вместо этого выполнить сортировку значений по убыванию, необходимо указать ключевое слово DESC.
Дополнительные сведения о предложении ORDER BY см. в статье Предложение ORDER BY .
Работа со сводными данными: предложения GROUP BY и HAVING
Иногда возникает необходимость работы со сводными данными, такими как итоговые продажи за месяц или самые дорогие товары на складе. Для этого в предложении SELECT к полю применяется агрегатная функция. Например, если в результате выполнения запроса нужно получить количество адресов электронной почты каждой компании, предложение SELECT может выглядеть следующим образом:
Возможность использования той или иной агрегатной функции зависит от типа данных в поле и нужного выражения. Дополнительные сведения о доступных агрегатных функциях см. в статье Статистические функции SQL .
Задание полей, которые не используются в агрегатной функции: предложение GROUP BY
При использовании агрегатных функций обычно необходимо создать предложение GROUP BY. В предложении GROUP BY указываются все поля, к которым не применяется агрегатная функция. Если агрегатные функции применяются ко всем полям в запросе, предложение GROUP BY создавать не нужно.
Предложение GROUP BY должно следовать сразу же за предложением WHERE или FROM, если предложение WHERE отсутствует. В предложении GROUP BY поля указываются в том же порядке, что и в предложении SELECT.
Продолжим предыдущий пример. Пусть в предложении SELECT агрегатная функция применяется только к полю [Адрес электронной почты], тогда предложение GROUP BY будет выглядеть следующим образом:
GROUP BY Company
Дополнительные сведения о предложении GROUP BY см. в статье Предложение GROUP BY .
Ограничение агрегированных значений с помощью условий группировки: предложение HAVING
Если необходимо указать условия для ограничения результатов, но поле, к которому их требуется применить, используется в агрегированной функции, предложение WHERE использовать нельзя. Вместо него следует использовать предложение HAVING. Предложение HAVING работает так же, как и WHERE, но используется для агрегированных данных.
Предположим, например, что к первому полю в предложении SELECT применяется функция AVG (которая вычисляет среднее значение):
SELECT COUNT(), Company
Если вы хотите ограничить результаты запроса на основе значения функции COUNT, к этому полю нельзя применить условие отбора в предложении WHERE. Вместо него условие следует поместить в предложение HAVING. Например, если нужно, чтобы запрос возвращал строки только в том случае, если у компании есть несколько адресов электронной почты, можно использовать следующее предложение HAVING:
HAVING COUNT()>1
Примечание: Запрос может включать и предложение WHERE, и предложение HAVING, при этом условия отбора для полей, которые не используются в статистических функциях, указываются в предложении WHERE, а условия для полей, которые используются в статистических функциях, - в предложении HAVING.
Дополнительные сведения о предложении HAVING см. в статье Предложение HAVING .
Объединение результатов запроса: оператор UNION
Оператор UNION используется для одновременного просмотра всех данных, возвращаемых несколькими сходными запросами на выборку, в виде объединенного набора.
Оператор UNION позволяет объединить две инструкции SELECT в одну. Объединяемые инструкции SELECT должны иметь одинаковое число и порядок выходных полей с такими же или совместимыми типами данных. При выполнении запроса данные из каждого набора соответствующих полей объединяются в одно выходное поле, поэтому выходные данные запроса имеют столько же полей, сколько и каждая инструкция SELECT по отдельности.
Примечание: В запросах на объединение числовой и текстовый типы данных являются совместимыми.
Используя оператор UNION, можно указать, должны ли в результаты запроса включаться повторяющиеся строки, если таковые имеются. Для этого следует использовать ключевое слово ALL.
Запрос на объединение двух инструкций SELECT имеет следующий базовый синтаксис:
SELECT field_1
FROM table_1
UNION
SELECT field_a
FROM table_a
;
Предположим, например, что имеется две таблицы, которые называются "Товары" и "Услуги". Обе таблицы содержат поля с названием товара или услуги, ценой и сведениями о гарантии, а также поле, в котором указывается эксклюзивность предлагаемого товара или услуги. Несмотря на то, что в таблицах "Продукты" и "Услуги" предусмотрены разные типы гарантий, основная информация одна и та же (предоставляется ли на отдельные продукты или услуги гарантия качества). Для объединения четырех полей из двух таблиц можно использовать следующий запрос на объединение:
SELECT name, price, warranty_available, exclusive_offer
FROM Products
UNION ALL
SELECT name, price, guarantee_available, exclusive_offer
FROM Services
;
Дополнительные сведения об объединении инструкций SELECT с помощью оператора UNION см. в статье