Разработка нейронных сетей. Изучаем нейронные сети за четыре шага. Нейросети постоянно самообучаются. Благодаря этому процессу
Нейронная сеть — попытка с помощью математических моделей воспроизвести работу человеческого мозга для создания машин, обладающих искусственным интеллектом.
Искусственная нейронная сеть обычно обучается с учителем. Это означает наличие обучающего набора (датасета), который содержит примеры с истинными значениями: тегами, классами, показателями.
Неразмеченные наборы также используют для обучения нейронных сетей, но мы не будем здесь это рассматривать.
Например, если вы хотите создать нейросеть для оценки тональности текста, датасетом будет список предложений с соответствующими каждому эмоциональными оценками. Тональность текста определяют признаки (слова, фразы, структура предложения), которые придают негативную или позитивную окраску. Веса признаков в итоговой оценке тональности текста (позитивный, негативный, нейтральный) зависят от математической функции, которая вычисляется во время обучения нейронной сети.
Раньше люди генерировали признаки вручную. Чем больше признаков и точнее подобраны веса, тем точнее ответ. Нейронная сеть автоматизировала этот процесс.

Искусственная нейронная сеть состоит из трех компонентов:
- Входной слой;
- Скрытые (вычислительные) слои;
- Выходной слой.

Обучение нейросетей происходит в два этапа:
- Обратное распространение ошибки.
Во время прямого распространения ошибки делается предсказание ответа. При обратном распространении ошибка между фактическим ответом и предсказанным минимизируется.
 Прямое распространение
Прямое распространение
Зададим начальные веса случайным образом:
Умножим входные данные на веса для формирования скрытого слоя:
- h1 = (x1 * w1) + (x2 * w1)
- h2 = (x1 * w2) + (x2 * w2)
- h3 = (x1 * w3) + (x2 * w3)
Выходные данные из скрытого слоя передается через нелинейную функцию (функцию активации), для получения выхода сети:
- y_ = fn(h1 , h2, h3)
Обратное распространение

- Суммарная ошибка (total_error) вычисляется как разность между ожидаемым значением «y» (из обучающего набора) и полученным значением «y_» (посчитанное на этапе прямого распространения ошибки), проходящих через функцию потерь (cost function).
- Частная производная ошибки вычисляется по каждому весу (эти частные дифференциалы отражают вклад каждого веса в общую ошибку (total_loss)).
- Затем эти дифференциалы умножаются на число, называемое скорость обучения или learning rate (η).
Полученный результат затем вычитается из соответствующих весов.
В результате получатся следующие обновленные веса:
- w1 = w1 — (η * ∂(err) / ∂(w1))
- w2 = w2 — (η * ∂(err) / ∂(w2))
- w3 = w3 — (η * ∂(err) / ∂(w3))
То, что мы предполагаем и инициализируем веса случайным образом, и они будут давать точные ответы, звучит не вполне обоснованно, тем не менее, работает хорошо.
 Популярный мем о том, как Карлсон стал Data Science разработчиком
Популярный мем о том, как Карлсон стал Data Science разработчиком
 Если вы знакомы с рядами Тейлора, обратное распространение ошибки имеет такой же конечный результат. Только вместо бесконечного ряда мы пытаемся оптимизировать только его первый член.
Если вы знакомы с рядами Тейлора, обратное распространение ошибки имеет такой же конечный результат. Только вместо бесконечного ряда мы пытаемся оптимизировать только его первый член.
Смещения – это веса, добавленные к скрытым слоям. Они тоже случайным образом инициализируются и обновляются так же, как скрытый слой. Роль скрытого слоя заключается в том, чтобы определить форму базовой функции в данных, в то время как роль смещения – сдвинуть найденную функцию в сторону так, чтобы она частично совпала с исходной функцией.
Частные производные
Частные производные можно вычислить, поэтому известно, какой был вклад в ошибку по каждому весу. Необходимость производных очевидна. Представьте нейронную сеть, пытающуюся найти оптимальную скорость беспилотного автомобиля. Eсли машина обнаружит, что она едет быстрее или медленнее требуемой скорости, нейронная сеть будет менять скорость, ускоряя или замедляя автомобиль. Что при этом ускоряется/замедляется? Производные скорости.
Разберем необходимость частных производных на примере.
Предположим, детей попросили бросить дротик в мишень, целясь в центр. Вот результаты:

Теперь, если мы найдем общую ошибку и просто вычтем ее из всех весов, мы обобщим ошибки, допущенные каждым. Итак, скажем, ребенок попал слишком низко, но мы просим всех детей стремиться попадать в цель, тогда это приведет к следующей картине:

Ошибка нескольких детей может уменьшиться, но общая ошибка все еще увеличивается.
Найдя частные производные, мы узнаем ошибки, соответствующие каждому весу в отдельности. Если выборочно исправить веса, можно получить следующее:

Гиперпараметры
Нейронная сеть используется для автоматизации отбора признаков, но некоторые параметры настраиваются вручную.
Скорость обучения (learning rate)
Скорость обучения является очень важным гиперпараметром. Если скорость обучения слишком мала, то даже после обучения нейронной сети в течение длительного времени она будет далека от оптимальных результатов. Результаты будут выглядеть примерно так:

С другой стороны, если скорость обучения слишком высока, то сеть очень быстро выдаст ответы. Получится следующее:

Функция активации (activation function)
Функция активации — это один из самых мощных инструментов, который влияет на силу, приписываемую нейронным сетям. Отчасти, она определяет, какие нейроны будут активированы, другими словами и какая информация будет передаваться последующим слоям.
Без функций активации глубокие сети теряют значительную часть своей способности к обучению. Нелинейность этих функций отвечает за повышение степени свободы, что позволяет обобщать проблемы высокой размерности в более низких измерениях. Ниже приведены примеры распространенных функций активации:

Функция потери (loss function)
Функция потерь находится в центре нейронной сети. Она используется для расчета ошибки между реальными и полученными ответами. Наша глобальная цель — минимизировать эту ошибку. Таким образом, функция потерь эффективно приближает обучение нейронной сети к этой цели.
Функция потерь измеряет «насколько хороша» нейронная сеть в отношении данной обучающей выборки и ожидаемых ответов. Она также может зависеть от таких переменных, как веса и смещения.
Функция потерь одномерна и не является вектором, поскольку она оценивает, насколько хорошо нейронная сеть работает в целом.
Некоторые известные функции потерь:
- Квадратичная (среднеквадратичное отклонение);
- Кросс-энтропия;
- Экспоненциальная (AdaBoost);
- Расстояние Кульбака - Лейблера или прирост информации.
Cреднеквадратичное отклонение – самая простая фукция потерь и наиболее часто используемая. Она задается следующим образом:

Функция потерь в нейронной сети должна удовлетворять двум условиям:
- Функция потерь должна быть записана как среднее;
- Функция потерь не должна зависеть от каких-либо активационных значений нейронной сети, кроме значений, выдаваемых на выходе.
Глубокие нейронные сети
Глубокое обучение (deep learning) – это класс алгоритмов машинного обучения, которые учатся глубже (более абстрактно) понимать данные. Популярные алгоритмы нейронных сетей глубокого обучения представлены на схеме ниже.
 Популярные алгоритмы нейронных сетей (http://www.asimovinstitute.org/neural-network-zoo)
Популярные алгоритмы нейронных сетей (http://www.asimovinstitute.org/neural-network-zoo)
Более формально в deep learning:
- Используется каскад (пайплайн, как последовательно передаваемый поток) из множества обрабатывающих слоев (нелинейных) для извлечения и преобразования признаков;
- Основывается на изучении признаков (представлении информации) в данных без обучения с учителем. Функции более высокого уровня (которые находятся в последних слоях) получаются из функций нижнего уровня (которые находятся в слоях начальных слоях);
- Изучает многоуровневые представления, которые соответствуют разным уровням абстракции; уровни образуют иерархию представления.
Пример
Рассмотрим однослойную нейронную сеть:

Здесь, обучается первый слой (зеленые нейроны), он просто передается на выход.
В то время как в случае двухслойной нейронной сети, независимо от того, как обучается зеленый скрытый слой, он затем передается на синий скрытый слой, где продолжает обучаться:

Следовательно, чем больше число скрытых слоев, тем больше возможности обучения сети.

Не следует путать с широкой нейронной сетью.
В этом случае большое число нейронов в одном слое не приводит к глубокому пониманию данных. Но это приводит к изучению большего числа признаков.
Пример:
Изучая английскую грамматику, требуется знать огромное число понятий. В этом случае однослойная широкая нейронная сеть работает намного лучше, чем глубокая нейронная сеть, которая значительно меньше.
В случае изучения преобразования Фурье, ученик (нейронная сеть) должен быть глубоким, потому что не так много понятий, которые нужно знать, но каждое из них достаточно сложное и требует глубокого понимания.
Главное — баланс
Очень заманчиво использовать глубокие и широкие нейронные сети для каждой задачи. Но это может быть плохой идеей, потому что:
- Обе требуют значительно большего количества данных для обучения, чтобы достичь минимальной желаемой точности;
- Обе имеют экспоненциальную сложность;
- Слишком глубокая нейронная сеть попытается сломать фундаментальные представления, но при этом она будет делать ошибочные предположения и пытаться найти псевдо-зависимости, которые не существуют;
- Слишком широкая нейронная сеть будет пытаться найти больше признаков, чем есть. Таким образом, подобно предыдущей, она начнет делать неправильные предположения о данных.
Проклятье размерности
Проклятие размерности относится к различным явлениям, возникающим при анализе и организации данных в многомерных пространствах (часто с сотнями или тысячами измерений), и не встречается в ситуациях с низкой размерностью.
Грамматика английского языка имеет огромное количество аттрибутов, влияющих на нее. В машинном обучении мы должны представить их признаками в виде массива/матрицы конечной и существенно меньшей длины (чем количество существующих признаков). Для этого сети обобщают эти признаки. Это порождает две проблемы:
- Из-за неправильных предположений появляется смещение. Высокое смещение может привести к тому, что алгоритм пропустит существенную взаимосвязь между признаками и целевыми переменными. Это явление называют недообучение.
- От небольших отклонений в обучающем множестве из-за недостаточного изучения признаков увеличивается дисперсия. Высокая дисперсия ведет к переобучению, ошибки воспринимаются в качестве надежной информации.
Компромисс
На ранней стадии обучения смещение велико, потому что выход из сети далек от желаемого. А дисперсия очень мала, поскольку данные имеет пока малое влияние.
В конце обучения смещение невелико, потому что сеть выявила основную функцию в данных. Однако, если обучение слишком продолжительное, сеть также изучит шум, характерный для этого набора данных. Это приводит к большому разбросу результатов при тестировании на разных множествах, поскольку шум меняется от одного набора данных к другому.
Действительно,

алгоритмы с большим смещением обычно в основе более простых моделей, которые не склонны к переобучению, но могут недообучиться и не выявить важные закономерности или свойства признаков. Модели с маленьким смещением и большой дисперсией обычно более сложны с точки зрения их структуры, что позволяет им более точно представлять обучающий набор. Однако они могут отображать много шума из обучающего набора, что делает их прогнозы менее точными, несмотря на их дополнительную сложность.
Следовательно, как правило, невозможно иметь маленькое смещение и маленькую дисперсию одновременно.
Сейчас есть множество инструментов, с помощью которых можно легко создать сложные модели машинного обучения, переобучение занимает центральное место. Поскольку смещение появляется, когда сеть не получает достаточно информации. Но чем больше примеров, тем больше появляется вариантов зависимостей и изменчивостей в этих корреляциях.
Джеймс Лой, Технологический университет штата Джорджия. Руководство для новичков, после которого вы сможете создать собственную нейронную сеть на Python.
Мотивация: ориентируясь на личный опыт в изучении глубокого обучения, я решил создать нейронную сеть с нуля без сложной учебной библиотеки, такой как, например, . Я считаю, что для начинающего Data Scientist-а важно понимание внутренней структуры нейронной сети.
Эта статья содержит то, что я усвоил, и, надеюсь, она будет полезна и для вас! Другие полезные статьи по теме:
Что такое нейронная сеть?
Большинство статей по нейронным сетям при их описании проводят параллели с мозгом. Мне проще описать нейронные сети как математическую функцию, которая отображает заданный вход в желаемый результат, не вникая в подробности.
Нейронные сети состоят из следующих компонентов:
- входной слой, x
- произвольное количество скрытых слоев
- выходной слой, ŷ
- набор весов и смещений между каждым слоем W и b
- выбор функции активации для каждого скрытого слоя σ ; в этой работе мы будем использовать функцию активации Sigmoid
На приведенной ниже диаграмме показана архитектура двухслойной нейронной сети (обратите внимание, что входной уровень обычно исключается при подсчете количества слоев в нейронной сети).
Создание класса Neural Network на Python выглядит просто:
Обучение нейронной сети
Выход ŷ простой двухслойной нейронной сети:
В приведенном выше уравнении, веса W и смещения b являются единственными переменными, которые влияют на выход ŷ.
Естественно, правильные значения для весов и смещений определяют точность предсказаний. Процесс тонкой настройки весов и смещений из входных данных известен как обучение нейронной сети.
Каждая итерация обучающего процесса состоит из следующих шагов
- вычисление прогнозируемого выхода ŷ, называемого прямым распространением
- обновление весов и смещений, называемых обратным распространением
Последовательный график ниже иллюстрирует процесс:

Прямое распространение
Как мы видели на графике выше, прямое распространение - это просто несложное вычисление, а для базовой 2-слойной нейронной сети вывод нейронной сети дается формулой:
Давайте добавим функцию прямого распространения в наш код на Python-е, чтобы сделать это. Заметим, что для простоты, мы предположили, что смещения равны 0.
Однако нужен способ оценить «добротность» наших прогнозов, то есть насколько далеки наши прогнозы). Функция потери как раз позволяет нам сделать это.
Функция потери
Есть много доступных функций потерь, и характер нашей проблемы должен диктовать нам выбор функции потери. В этой работе мы будем использовать сумму квадратов ошибок в качестве функции потери.

Сумма квадратов ошибок - это среднее значение разницы между каждым прогнозируемым и фактическим значением.
Цель обучения - найти набор весов и смещений, который минимизирует функцию потери.
Обратное распространение
Теперь, когда мы измерили ошибку нашего прогноза (потери), нам нужно найти способ распространения ошибки обратно и обновить наши веса и смещения.
Чтобы узнать подходящую сумму для корректировки весов и смещений, нам нужно знать производную функции потери по отношению к весам и смещениям.
Напомним из анализа, что производная функции - это тангенс угла наклона функции.

Если у нас есть производная, то мы можем просто обновить веса и смещения, увеличив/уменьшив их (см. диаграмму выше). Это называется градиентным спуском .
Однако мы не можем непосредственно вычислить производную функции потерь по отношению к весам и смещениям, так как уравнение функции потерь не содержит весов и смещений. Поэтому нам нужно правило цепи для помощи в вычислении.
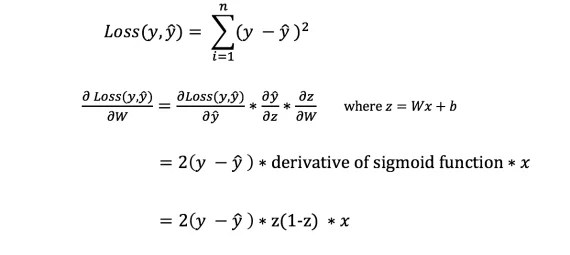
Фух! Это было громоздко, но позволило получить то, что нам нужно - производную (наклон) функции потерь по отношению к весам. Теперь мы можем соответствующим образом регулировать веса.
Добавим функцию backpropagation (обратного распространения) в наш код на Python-е:
Проверка работы нейросети
Теперь, когда у нас есть наш полный код на Python-е для выполнения прямого и обратного распространения, давайте рассмотрим нашу нейронную сеть на примере и посмотрим, как это работает.
 Идеальный набор весов
Идеальный набор весов
Наша нейронная сеть должна изучить идеальный набор весов для представления этой функции.
Давайте тренируем нейронную сеть на 1500 итераций и посмотрим, что произойдет. Рассматривая график потерь на итерации ниже, мы можем ясно видеть, что потеря монотонно уменьшается до минимума. Это согласуется с алгоритмом спуска градиента, о котором мы говорили ранее.
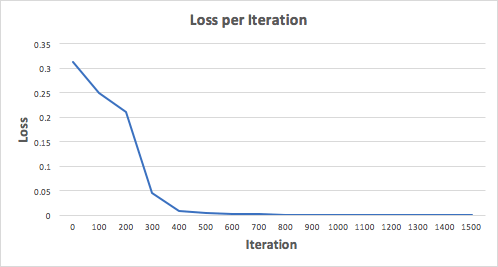
Посмотрим на окончательное предсказание (вывод) из нейронной сети после 1500 итераций.

Мы сделали это! Наш алгоритм прямого и обратного распространения показал успешную работу нейронной сети, а предсказания сходятся на истинных значениях.
Заметим, что есть небольшая разница между предсказаниями и фактическими значениями. Это желательно, поскольку предотвращает переобучение и позволяет нейронной сети лучше обобщать невидимые данные.
Финальные размышления
Я многому научился в процессе написания с нуля своей собственной нейронной сети. Хотя библиотеки глубинного обучения, такие как TensorFlow и Keras, допускают создание глубоких сетей без полного понимания внутренней работы нейронной сети, я нахожу, что начинающим Data Scientist-ам полезно получить более глубокое их понимание.
Я инвестировал много своего личного времени в данную работу, и я надеюсь, что она будет полезной для вас!
В последнее время все чаще и чаще говорят про так званные нейронные сети, дескать вскоре они будут активно применятся и в роботехнике, и в машиностроении, и во многих других сферах человеческой деятельности, ну а алгоритмы поисковых систем, того же Гугла уже потихоньку начинают на них работать. Что же представляют собой эти нейронные сети, как они работают, какое у них применение и чем они могут стать полезными для нас, обо всем этом читайте дальше.
Что такое нейронные сети
Нейронные сети – это одно из направлений научных исследований в области создания искусственного интеллекта (ИИ) в основе которого лежит стремление имитировать нервную систему человека. В том числе ее (нервной системы) способность исправлять ошибки и самообучаться. Все это, хотя и несколько грубо должно позволить смоделировать работу человеческого мозга.
Биологические нейронные сети
Но это определение абзацем выше чисто техническое, если же говорить языком биологии, то нейронная сеть представляет собой нервную систему человека, ту совокупность нейронов в нашем мозге, благодаря которым мы думаем, принимаем те или иные решения, воспринимаем мир вокруг нас.
Биологический нейрон – это специальная клетка, состоящая из ядра, тела и отростков, к тому же имеющая тесную связь с тысячами других нейронов. Через эту связь то и дело передаются электрохимические импульсы, приводящие всю нейронную сеть в состояние возбуждение или наоборот спокойствия. Например, какое-то приятное и одновременно волнующее событие (встреча любимого человека, победа в соревновании и т. д.) породит электрохимический импульс в нейронной сети, которая располагается в нашей голове, что приведет к ее возбуждению. Как следствие, нейронная сеть в нашем мозге свое возбуждение передаст и другим органам нашего тела и приведет к повышенному сердцебиению, более частому морганию глаз и т. д.
Тут на картинке приведена сильно упрощенная модель биологической нейронной сети мозга. Мы видим, что нейрон состоит из тела клетки и ядра, тело клетки, в свою очередь, имеет множество ответвленных волокон, названых дендритами. Длинные дендриты называются аксонами и имеют протяженность много большую, нежели показано на этом рисунке, посредством аксонов осуществляется связь между нейронами, благодаря ним и работает биологическая нейронная сеть в наших с вами головах.
История нейронных сетей
Какова же история развития нейронных сетей в науке и технике? Она берет свое начало с появлением первых компьютеров или ЭВМ (электронно-вычислительная машина) как их называли в те времена. Так еще в конце 1940-х годов некто Дональд Хебб разработал механизм нейронной сети, чем заложил правила обучения ЭВМ, этих «протокомпьютеров».
Дальнейшая хронология событий была следующей:
- В 1954 году происходит первое практическое использование нейронных сетей в работе ЭВМ.
- В 1958 году Франком Розенблатом разработан алгоритм распознавания образов и математическая аннотация к нему.
- В 1960-х годах интерес к разработке нейронных сетей несколько угас из-за слабых мощностей компьютеров того времени.
- И снова возродился уже в 1980-х годах, именно в этот период появляется система с механизмом обратной связи, разрабатываются алгоритмы самообучения.
- К 2000 году мощности компьютеров выросли настолько, что смогли воплотить самые смелые мечты ученых прошлого. В это время появляются программы распознавания голоса, компьютерного зрения и многое другое.

Искусственные нейронные сети
Под искусственными нейронными сетями принято понимать вычислительные системы, имеющие способности к самообучению, постепенному повышению своей производительности. Основными элементами структуры нейронной сети являются:
- Искусственные нейроны, представляющие собой элементарные, связанные между собой единицы.
- – это соединение, которые используется для отправки-получения информации между нейронами.
- Сигнал – собственно информация, подлежащая передаче.
Применение нейронных сетей
Область применения искусственных нейронных сетей с каждым годом все более расширяется, на сегодняшний день они используются в таких сферах как:
- Машинное обучение (machine learning), представляющее собой разновидность искусственного интеллекта. В основе его лежит обучение ИИ на примере миллионов однотипных задач. В наше время машинное обучение активно внедряют поисковые системы Гугл, Яндекс, Бинг, Байду. Так на основе миллионов поисковых запросов, которые все мы каждый день вводим в Гугле, их алгоритмы учатся показывать нам наиболее релевантную выдачу, чтобы мы могли найти именно то, что ищем.
- В роботехнике нейронные сети используются в выработке многочисленных алгоритмов для железных «мозгов» роботов.
- Архитекторы компьютерных систем пользуются нейронными сетями для решения проблемы параллельных вычислений.
- С помощью нейронных сетей математики могут разрешать разные сложные математические задачи.
Типы нейронных сетей
В целом для разных задач применяются различные виды и типы нейронных сетей, среди которых можно выделить:
- сверточные нейронные сети,
- реккурентные нейронные сети,
- нейронную сеть Хопфилда.

Сверточные нейронные сети
Сверточные сети являются одними из самых популярных типов искусственных нейронных сетей. Так они доказали свою эффективность в распознавании визуальных образов (видео и изображения), рекомендательных системах и обработке языка.
- Сверточные нейронные сети отлично масштабируются и могут использоваться для распознавания образов, какого угодно большого разрешения.
- В этих сетях используются объемные трехмерные нейроны. Внутри одного слоя нейроны связаны лишь небольшим полем, названые рецептивным слоем.
- Нейроны соседних слоев связаны посредством механизма пространственной локализации. Работу множества таких слоев обеспечивают особые нелинейные фильтры, реагирующие на все большее число пикселей.
Рекуррентные нейронные сети
Рекуррентными называют такие нейронные сети, соединения между нейронами которых, образуют ориентировочный цикл. Имеет такие характеристики:
- У каждого соединения есть свой вес, он же приоритет.
- Узлы делятся на два типа, вводные узлы и узлы скрытые.
- Информация в рекуррентной нейронной сети передается не только по прямой, слой за слоем, но и между самими нейронами.
- Важной отличительной особенностью рекуррентной нейронной сети является наличие так званой «области внимания», когда машине можно задать определенные фрагменты данных, требующие усиленной обработки.
Рекуррентные нейронные сети применяются в распознавании и обработке текстовых данных (в частотности на их основе работает Гугл переводчик, алгоритм Яндекс «Палех», голосовой помощник Apple Siri).
Нейронные сети, видео
И в завершение интересное видео о нейронных сетях.

При написании статьи старался сделать ее максимально интересной, полезной и качественной. Буду благодарен за любую обратную связь и конструктивную критику в виде комментариев к статье. Также Ваше пожелание/вопрос/предложение можете написать на мою почту [email protected] или в Фейсбук, с уважением автор.
Мое знакомство с нейронными сетями произошло, когда вышло приложение Prisma. Оно обрабатывает любую фотографию, с помощью нейронных сетей, и воспроизводит ее с нуля, используя выбранный стиль. Заинтересовавшись этим, я бросился искать статьи и «туториалы», в первую очередь, на Хабре. И к моему великому удивлению, я не нашел ни одну статью, которая четко и поэтапно расписывала алгоритм работы нейронных сетей. Информация была разрознена и в ней отсутствовали ключевые моменты. Также, большинство авторов бросается показывать код на том или ином языке программирования, не прибегая к детальным объяснениям.
П ервым и самым важным моим открытием был плейлист американского программиста Джеффа Хитона, в котором он подробно и наглядно разбирает принципы работы нейронных сетей и их классификации. После просмотра этого плейлиста, я решил создать свою нейронную сеть, начав с самого простого примера. Вам наверняка известно, что когда ты только начинаешь учить новый язык, первой твоей программой будет Hello World. Это своего рода традиция. В мире машинного обучения тоже есть свой Hello world и это нейросеть решающая проблему исключающего или(XOR). Таблица исключающего или выглядит следующим образом:
Соответственно, нейронная сеть берет на вход два числа и должна на выходе дать другое число - ответ. Теперь о самих нейронных сетях.
Что такое нейронная сеть?
Нейронная сеть - это последовательность нейронов, соединенных между собой синапсами. Структура нейронной сети пришла в мир программирования прямиком из биологии. Благодаря такой структуре, машина обретает способность анализировать и даже запоминать различную информацию. Нейронные сети также способны не только анализировать входящую информацию, но и воспроизводить ее из своей памяти. Заинтересовавшимся обязательно к просмотру 2 видео из TED Talks: Видео 1 , Видео 2 ). Другими словами, нейросеть это машинная интерпретация мозга человека, в котором находятся миллионы нейронов передающих информацию в виде электрических импульсов.
Какие бывают нейронные сети?
Пока что мы будем рассматривать примеры на самом базовом типе нейронных сетей - это сеть прямого распространения (далее СПР). Также в последующих статьях я введу больше понятий и расскажу вам о рекуррентных нейронных сетях. СПР как вытекает из названия это сеть с последовательным соединением нейронных слоев, в ней информация всегда идет только в одном направлении.
Для чего нужны нейронные сети?
Нейронные сети используются для решения сложных задач, которые требуют аналитических вычислений подобных тем, что делает человеческий мозг. Самыми распространенными применениями нейронных сетей является:
Классификация - распределение данных по параметрам. Например, на вход дается набор людей и нужно решить, кому из них давать кредит, а кому нет. Эту работу может сделать нейронная сеть, анализируя такую информацию как: возраст, платежеспособность, кредитная история и тд.
Предсказание - возможность предсказывать следующий шаг. Например, рост или падение акций, основываясь на ситуации на фондовом рынке.
Распознавание - в настоящее время, самое широкое применение нейронных сетей. Используется в Google, когда вы ищете фото или в камерах телефонов, когда оно определяет положение вашего лица и выделяет его и многое другое.
Теперь, чтобы понять, как же работают нейронные сети, давайте взглянем на ее составляющие и их параметры.
Что такое нейрон?

Нейрон - это вычислительная единица, которая получает информацию, производит над ней простые вычисления и передает ее дальше. Они делятся на три основных типа: входной (синий), скрытый (красный) и выходной (зеленый). Также есть нейрон смещения и контекстный нейрон о которых мы поговорим в следующей статье. В том случае, когда нейросеть состоит из большого количества нейронов, вводят термин слоя. Соответственно, есть входной слой, который получает информацию, n скрытых слоев (обычно их не больше 3), которые ее обрабатывают и выходной слой, который выводит результат. У каждого из нейронов есть 2 основных параметра: входные данные (input data) и выходные данные (output data). В случае входного нейрона: input=output. В остальных, в поле input попадает суммарная информация всех нейронов с предыдущего слоя, после чего, она нормализуется, с помощью функции активации (пока что просто представим ее f(x)) и попадает в поле output.

Важно помнить , что нейроны оперируют числами в диапазоне или [-1,1]. А как же, вы спросите, тогда обрабатывать числа, которые выходят из данного диапазона? На данном этапе, самый простой ответ - это разделить 1 на это число. Этот процесс называется нормализацией, и он очень часто используется в нейронных сетях. Подробнее об этом чуть позже.
Что такое синапс?

Синапс это связь между двумя нейронами. У синапсов есть 1 параметр - вес. Благодаря ему, входная информация изменяется, когда передается от одного нейрона к другому. Допустим, есть 3 нейрона, которые передают информацию следующему. Тогда у нас есть 3 веса, соответствующие каждому из этих нейронов. У того нейрона, у которого вес будет больше, та информация и будет доминирующей в следующем нейроне (пример - смешение цветов). На самом деле, совокупность весов нейронной сети или матрица весов - это своеобразный мозг всей системы. Именно благодаря этим весам, входная информация обрабатывается и превращается в результат.
Важно помнить , что во время инициализации нейронной сети, веса расставляются в случайном порядке.
Как работает нейронная сеть?

В данном примере изображена часть нейронной сети, где буквами I обозначены входные нейроны, буквой H - скрытый нейрон, а буквой w - веса. Из формулы видно, что входная информация - это сумма всех входных данных, умноженных на соответствующие им веса. Тогда дадим на вход 1 и 0. Пусть w1=0.4 и w2 = 0.7 Входные данные нейрона Н1 будут следующими: 1*0.4+0*0.7=0.4. Теперь когда у нас есть входные данные, мы можем получить выходные данные, подставив входное значение в функцию активации (подробнее о ней далее). Теперь, когда у нас есть выходные данные, мы передаем их дальше. И так, мы повторяем для всех слоев, пока не дойдем до выходного нейрона. Запустив такую сеть в первый раз мы увидим, что ответ далек от правильно, потому что сеть не натренирована. Чтобы улучшить результаты мы будем ее тренировать. Но прежде чем узнать как это делать, давайте введем несколько терминов и свойств нейронной сети.
Функция активации
Функция активации - это способ нормализации входных данных (мы уже говорили об этом ранее). То есть, если на входе у вас будет большое число, пропустив его через функцию активации, вы получите выход в нужном вам диапазоне. Функций активации достаточно много поэтому мы рассмотрим самые основные: Линейная, Сигмоид (Логистическая) и Гиперболический тангенс. Главные их отличия - это диапазон значений.
Линейная функция

Эта функция почти никогда не используется, за исключением случаев, когда нужно протестировать нейронную сеть или передать значение без преобразований.
Сигмоид

Это самая распространенная функция активации, ее диапазон значений . Именно на ней показано большинство примеров в сети, также ее иногда называют логистической функцией. Соответственно, если в вашем случае присутствуют отрицательные значения (например, акции могут идти не только вверх, но и вниз), то вам понадобиться функция которая захватывает и отрицательные значения.
Гиперболический тангенс

Имеет смысл использовать гиперболический тангенс, только тогда, когда ваши значения могут быть и отрицательными, и положительными, так как диапазон функции [-1,1]. Использовать эту функцию только с положительными значениями нецелесообразно так как это значительно ухудшит результаты вашей нейросети.
Тренировочный сет
Тренировочный сет - это последовательность данных, которыми оперирует нейронная сеть. В нашем случае исключающего или (xor) у нас всего 4 разных исхода то есть у нас будет 4 тренировочных сета: 0xor0=0, 0xor1=1, 1xor0=1,1xor1=0.
Итерация
Это своеобразный счетчик, который увеличивается каждый раз, когда нейронная сеть проходит один тренировочный сет. Другими словами, это общее количество тренировочных сетов пройденных нейронной сетью.
Эпоха
При инициализации нейронной сети эта величина устанавливается в 0 и имеет потолок, задаваемый вручную. Чем больше эпоха, тем лучше натренирована сеть и соответственно, ее результат. Эпоха увеличивается каждый раз, когда мы проходим весь набор тренировочных сетов, в нашем случае, 4 сетов или 4 итераций.

Важно не путать итерацию с эпохой и понимать последовательность их инкремента. Сначала n раз увеличивается итерация, а потом уже эпоха и никак не наоборот. Другими словами, нельзя сначала тренировать нейросеть только на одном сете, потом на другом и тд. Нужно тренировать каждый сет один раз за эпоху. Так, вы сможете избежать ошибок в вычислениях.
Ошибка
Ошибка - это процентная величина, отражающая расхождение между ожидаемым и полученным ответами. Ошибка формируется каждую эпоху и должна идти на спад. Если этого не происходит, значит, вы что-то делаете не так. Ошибку можно вычислить разными путями, но мы рассмотрим лишь три основных способа: Mean Squared Error (далее MSE), Root MSE и Arctan. Здесь нет какого-либо ограничения на использование, как в функции активации, и вы вольны выбрать любой метод, который будет приносить вам наилучший результат. Стоит лишь учитывать, что каждый метод считает ошибки по разному. У Arctan, ошибка, почти всегда, будет больше, так как он работает по принципу: чем больше разница, тем больше ошибка. У Root MSE будет наименьшая ошибка, поэтому, чаще всего, используют MSE, которая сохраняет баланс в вычислении ошибки.

Root MSE

Arctan

Принцип подсчета ошибки во всех случаях одинаков. За каждый сет, мы считаем ошибку, отняв от идеального ответа, полученный. Далее, либо возводим в квадрат, либо вычисляем квадратный тангенс из этой разности, после чего полученное число делим на количество сетов.
Задача
Теперь, чтобы проверить себя, подсчитайте результат, данной нейронной сети, используя сигмоид, и ее ошибку, используя MSE.
Данные:
I1=1, I2=0, w1=0.45, w2=0.78 ,w3=-0.12 ,w4=0.13 ,w5=1.5 ,w6=-2.3.

Решение
H1input = 1*0.45+0*-0.12=0.45
H1output = sigmoid(0.45)=0.61
H2input = 1*0.78+0*0.13=0.78
H2output = sigmoid(0.78)=0.69
O1input = 0.61*1.5+0.69*-2.3=-0.672
O1output = sigmoid(-0.672)=0.33
O1ideal = 1 (0xor1=1)
Error = ((1-0.33)^2)/1=0.45
Результат - 0.33, ошибка - 45%.
Большое спасибо за внимание! Надеюсь, что данная статья смогла помочь вам в изучении нейронных сетей. В следующей статье, я расскажу о нейронах смещения и о том, как тренировать нейронную сеть, используя метод обратного распространения и градиентного спуска.
Использованные ресурсы:
Пример программы нейронной сети с исходным кодом на с++.
Про нейронные сети хорошо и подробно написано здесь. Попытаемся разобраться как программировать нейронные сети, и как это работает . Одна из задач решаемых нейронными сетями, задача классификации. Программа демонстрирует работу нейронной сети классифицирующей цвет.
В компьютере принята трехкомпонентная модель представления цвета RGB, на каждый из компонентов отводится один байт. полный цвет представлен 24 битами, что дает 16 миллионов оттенков. Человек же может отнести любой из этих оттенков к одному из имеющих название цветов. Итак задача:
Дано InColor — цвет RGB (24 бит)
классифицировать цвет, т.е. отнести его к одному из цветов заданных множеством М={ Черный, Красный, Зеленый, Желтый, Синий, Фиолетовый, Голубой, Белый }.
OutColor — цвет из множества М
Решение номер 1. (цифровое)
Создаем массив размером 16777216 элементов
Решение номер 2. (аналоговое)
напишем функцию, типа
|
int8 GetColor(DWORD Color) |
Это будет работать если задачу можно описать простыми уравнениями, а вот если функция настолько сложна что описанию. не поддается, здесь то на помощь приходят нейронные сети.
Решение номер 3. (нейронная сеть)
Простейшая нейронная сеть. Однослойный перцептрон.
Все нейронное заключено в класс CNeuroNet
Каждый нейрон имеет 3 входа, куда подаются интенсивности компонент цвета. (R,G,B) в диапазоне (0 — 1). Всего нейронов 8, по количеству цветов в выходном множестве. В результате работы сети на выходе каждого нейрона формируется сигнал в диапазоне (0 — 1), который означает вероятность того что на входе этот цвет. Выбираем максимальный и получаем ответ.
Нейроны имеют сигмоидную функцию активации ActiveSigm(). Функция ActiveSigmPro(), производная от сигмоидной функции активации используется для обучения нейронной сетиметодом обратного распространения.
В первой строчке выведены интенсивности цветов. ниже таблица весовых коэффициентов (4 шт.). В последнем столбце значение на выходе нейронов. Меняем цвет, выбираем из списка правильный ответ, кнопкой Teach вызываем функцию обучения. AutoTeach вызывает процедуру автоматического обучения, 1000 раз, случайный цвет определяется по формуле из решения номер 2, и вызывается функция обучения.
скачать исходный код и программу нейронной сети

Программирование искусственных нейронных сетей — я пишу на С++ в объектно-ориентированной парадигме
Для простых нейроархитектур (структур), методов и задач можно использовать любой язык (даже Бэйсик), но для сложных проектов наиболее пригодными оказываются языки объектно-ориентированного программирования (такие, как С++). Я применяю именно С++, при необходимости (в наиболее времязатратных местах программы) переписывая отдельные функции (требующие ускорения вычислений) на инлайн-ассемблере.
Покажем пользу объектно-ориентированного подхода к программированию нейросеток. У нейросети может быть множество вариантов нейронов и/или слоёв (см. заметку про современные возможности собрать свёрточную нейросеть из большого числа разнотипных слоёв и нейронов). Некоторую общую функциональность нейронов или слоёв можно вынести в абстрактный класс-предок, порождая (наследуя) от него классы для тех или иных видов нейронов/слоёв (эти классы-потомки будут описывать-реализовывать уже уникальные для конкретного вида нейрона или слоя особенности и поведение). Таким образом обеспечиваются ликвидация многократного дублирования общих (одинаковых) вещей в тексте программы и возможность написать более гибкий и независимый от конкретных типов нейронов/слоёв управляющий код программы при использовании принципов полиморфизма.
В качестве примера рассмотрим номенклатуру классов для описания слоёв нейросети в одной из разработанных мной программ. Имеется 3 основных иерархии − одна для классов-описателей структуры слоя (цепочка наследования из трёх классов), вторая − для нелинейных функций нейронов (базовый класс и десять наследников от него), третья − для самих слоёв (цепочка из 5 базовых-промежуточных классов и 12 реальных классов, отпочковавшихся от этой цепочки на разных её уровнях).
Нейронные сети
в тексте программы для описания поведения слоёв сети использован (реализован) 31 класс, но при этом всего 12 из них реализуют реальные слои, а остальные классы:
- либо абстрактные, задающие общее поведение, позволяющие в дальнейшем более просто создавать новых потомков (новые типы слоёв) и повышающие степень инвариантности управляющей логики (реализующей функционирование нейронной сети) к составляющим сеть разнообразным слоям;
- либо, наоборот, являются подчинёнными и входят в состав слоя в качестве его «компонент» (экземпляр объекта-описателя структуры и характеристик слоя, и экземпляр объекта, реализующего нелинейную функцию нейронов).
Функционирование созданной нейронной сети запрограммировано через обращения к методам и свойствам абстрактных классов, независимо от того, какой конкретно класс-потомок реализует тот или иной слой нейросети.
Т.е. управляющая логика здесь отделена от конкретного содержания и привязана только к общим, инвариантным основам. О конкретных же классах необходимо знать только коду «конструктора» нейросети − работающего только в момент создания новой сети исходя из заданных в интерфейсе настроек или при загрузке ранее сохранённой сети из файла. Добавление новых типов слоёв нейронов в программу не приведёт к переделке алгоритмов (логики) работы и обучения сети − а потребует только небольшого дополнения кода механизмов создания (или чтения из файла) нейросети.
Абстракций (классов) для отдельных нейронов нет — только для слоёв. Если нужно поставить на некотором (а именно — на выходном) слое единственный нейрон — то просто экземпляру класса нужного нейронного слоя при создании передаётся счётчик числа нейронов, равный единице.
Таким образом, объектно-ориентированные проектирование и программирование обеспечивают бОльшую гибкость для реализации принципа «разделяй и властвуй» по сравнению со структурным программированием, через:
- вынос общих фрагментов кода в классы-предки (принцип наследования),
- обеспечение необходимого сокрытия информации (принцип инкапсуляции),
- построение-получение универсальной, независимой от конкретных реализаций классов, внешней управляющей логики (принцип полиморфизма).
- достижение кросс-платформенности через вынос аппаратно- или платформозависимых частей в классы-потомки (число которых может меняться под каждую конкретную программно-аппаратную реализацию, в то время, как число базовых классов-предков и вся логика высокого уровня будут одинаковы и неизменны).
Для современных задач разработки гибких и мощных инструментов нейромоделирования всё это оказывается очень полезным.
Также см. пост про проекты специальных языков описания ИНС.
нейронные сети,
методы анализа данных:
от исследований до разработок и внедрений
Главная
Услуги
Нейронные сети
базовые идеи
возможности
преимущества
области применения
как использовать
Точность решения
НС и ИИ
Программы
Статьи
Блог
Об авторе / контакты
Тонкая настройка Вселенной — это уникальное сочетание многочисленных свойств Вселенной такое, что только оно и способно обеспечить существование наблюдаемой Вселенной. Даже минимальные отклонения состава или значений этих свойств несовместимы с фактом существования Вселенной.
Обычно понятие тонкой настройки Вселенной рассматривается в слабой формулировке: принимаются во внимание значения всего нескольких мировых констант, и делается вывод только о невозможности существования человечества при их отклонениях. Такой ограниченный подход стимулирует религиозно окрашенные попытки объяснения этого явления, например, антропный принцип , декларирующий богоданную целесообразность Вселенной, заключенную в существовании человека.
Тонкая настройка Вселенной — это самая впечатляющая из аперцепций современной космологии: никакая другая не сравнится с ней по силе и убедительности свидетельства о Большом тупике, о том, что Вселенная устроена категорически не так, как её представляет современная наука, и в рамках этого представления исследует. Не несколько констант, а вообще непредставимо огромный корпус разнообразных фактов, имей любой из них даже небольшое отличие от наблюдаемого, сделал бы невозможным существование жизни и Вселенной. Значения свойств элементарных частиц (массы, заряды, периоды полураспада…), свойства фундаментальных взаимодействий, свойства веществ (да хотя бы воды), — всё это и многое-многое другое тщательно выбрано именно таким, чтобы Вселенная существовала. Любой из миллионов этих фактов, будь он другим, привёл бы её к несуществованию. Или, как минимум (в слабой формулировке) — к невозможности жизни в ней.
Искусственная нейронная сеть
Осознание этого полностью разрушает привычную "научную картину мира" эпохи Большого тупика. Но, как уже сказано, здесь имеет место аперцепция: люди отказываются осознавать это.
Объяснение тонкой настройки в ИТВ
ИТВ устанавливает, что Вселенная состоит только из информации. Наблюдатель наблюдает наблюдаемое, получая информацию — и это всё, что составляет Вселенную. Информация, будучи всего лишь описанием чего-либо, могла бы быть любой возможной, если бы она получалась сама по себе. Однако информация сама по себе ничем не является и ничего описывать не может, для этого всегда нужны некоторые условия, и они ограничивают содержание информации.
Таким образом, Вселенная — это совокупность обусловленных выборов конкретной наблюдаемой информации из широкой гаммы в принципе возможной. Существование Вселенной является финальным критерием всех этих выборов: они таковы постольку, поскольку Вселенная существует, будь они другими — Вселенная не существовала бы.
Это и есть тонкая настройка Вселенной: значения мировых констант и вообще все свойства Вселенной определились фактом существования Вселенной, никто их специально не подбирал, ни из какой единой константы они не выводятся, никакой возможности установить их иной состав и иные значения не существует.
Разбираем нейронную сеть. C#
В данной статье предлагаю разобрать дейтсвие нейронных сетей и накидать один из простейших вариантов нейронной сети, обучающейся при помощи учителя.
Пару слов, необходимо уделить устройству этой самой «великой» и «ужасной» нейронной сети. Долгое количество времени люди ходили взад и вперед и размышляли над вопросом: (в чем смысл жизни?)
Как можно распознавать образы?
Ответов было огромное множество. Тут и различные эвристики, и сравнения по шаблонам и многое-многое. Одним из ответов была нейронная сеть. [К слову сказать нейронная сеть может не только распознавать образы]
Итак. Структура нейронной сети. Представьте себе такую картину: паук сплел сеть и сеть словила муху. То место на которое попала муха и есть нейрон, который был «максимально» близок к цели. Нейронная сеть состоит из нейронов, которые «описывают»
шансы того или иного события. Описание «вероятности» события (каждого нейрона) может храниться (к примеру) в отдельном файле.
Теперь переходим к главной теме разговора этого вечера.
Как устроена нейронная сеть.
Как происходит ее обучение и распознание.
Пример структуры нейронной сети отчеливо виден на этой картинке:
На вход поступает множество входных сигналов X. Которые умножаются на множество весов W (Xi * Wi). В нейроне производится подсчет суммы произведений и на выход отправляется некоторое число.
После подсчета значений у всех нейронов, производится поиск наибольшего значения. Это наибольшее значение и считается корректным ответом на вопрос. Программой выдается образ, который описывается найденным нейроном.
В режиме обучения пользователь имеет возможность подправить результат (основываясь на своем опыте) и тогда программа произведет пересчет весов нейронов.
Формула перерасчета примерно следующая: W[i] = W[i] + Speed*Delta*X[i] — здесь
W[i] — вес i-го элемента,
Speed — скорость обучения,
Delta — знак (-1 или 1),
X[i] — значение i-го входящего сигнала (во многих случаях 0 или 1)
Зачем используется delta?
Разберем такой случай.
На вход программе подается картинка с цифрой 6.
На каком языке программирования писать нейронные сети?
Нейронная сеть распознала цифру 8. Пользователь правит цифру на 6. Что происходит далее в программе?
Программа пересчитывает данные для двух нейронов, описывающих число 6 и число 8, причем для нейрона, описывающего число 6 delta будет равна 1, а для 8 = -1
Как задается параметр скорости?
Данный параметр, чем меньше тем, дольше и точнее(качетственнее) будет происходить обучение сети, и чем больше, тем быстрее и «поверхностней» будет происходить обучение сети.
Параметр Speed может задаваться как вручную, пользователем, так и в ходе выполнения программы(к примеру const)
Как видно, весы символов также должны быть определены. А чем они определяются изначально? на самом деле тут также все просто. Определяются они совершенно случайно, это позволяет избежать «предвзятости» нейронной сети. Обычно, интервал случайных значений небольшой -0.4…0.4 или -0.3..0.2 и т.п.
Теперь переходим к самой интересной части. Как это закодировать!
Создадим два класса — класс Нейрон и класс Сеть (Neuron и Net соответственно)
Опишем основные задачи класса Neuron:
— Реакция на входной сигнал
— Суммирование
— Корректировка
(как дополнительно можно добавить чтение из файла, создание начальных значений, сохранение. Оставим это на «совести» читающих)
Переменные внутри класса Neuron:symbol
— Идентификатор «опознания» — LastY
— Описываемый образ — symbolsymbol