Что такое zfs. Резервная копия zfs. Отключение автомонтирования в ZFS
Предлагаемые заметки призваны осветить ключевые аспекты и заложить основы для понимания того, какие возможности и удобства предоставляет ZFS пользователю.
zpool
Если традиционно файловые системы создают на разделах носителей информации, то ZFS объединяет произвольное множество физических накопителей и их логических частей в пространство без границ, проще говоря поле (англ. pool ). При этом решение низкоуровневых вопросов ZFS берёт на себя, позволяя создать зеркальный массив из двух накопителей одной командой:
# zpool create pool mirror sdb sdc
Когда дублирование информации пользователя не требуется, носители информации можно объединить, сложив их ёмкости и увеличив скорость доступа:
# zpool create pool sdb sdc
В вышеприведённых примерах pool - произвольное имя создаваемого информационного поля. sdb и sdc - сокращения от путей /dev/sdb и /dev/sdc . Заметим, что в таком случае на каждом устройстве будут созданы GPT разметка и разделы:
Устр-во Start Конец Size Тип /dev/sdc1 2048 31487999 15G Solaris /usr & Apple ZFS /dev/sdc9 31488000 31504383 8M Solaris reserved 1
Можно передавать команде zpool create и имена существующих разделов (как обычно), а так же файлов (вариант предусмотрен для экспериментов).
Если поле создано на переносном накопителе, для безопасного отключения служит команда:
# zpool export pool
а для подключения:
# zpool import pool
Когда имя не известно, команда импорта выполняется без его указания и выводит список возможных.
Архитектура ZFS такова, что извлечение физического накопителя без предварительного экспорта исключает повреждение информации пользователя. Механизм транзакций сохраняет изменения в свободных секторах без перезаписи оригинала. Таким образом гарантируется целостность ФС и допускается потеря лишь не в полной мере записанных данных. Например, при аварийном отключении энергии непосредственно в процессе сохранения отредактированного документа на диске окажется прежняя версия. Для дополнительной защиты данных от ошибок (в том числе аппаратуры) ZFS использует контрольные суммы.
Запуск задачи очистки от повреждений производится командой:
# zpool scrub pool
а проверка состояния:
# zpool status
Произведённые операции сохраняются в журнале, для просмотра которого служит:
# zpool history
zfs
Создав вышеизложенным способом pool, можно обнаружить, что в коневом разделе смонтирован каталог с соответствующим именем. На самом деле, ему соответствует одноимённая файловая система, в чём можно убедиться, дав команду:
# zfs list
В таком виде уже возможно использовать ZFS - как обычную ФС. Если желательно монтировать традиционно, командой mount и посредством /etc/fstab , то следует изменить соответствующее свойство таким образом:
# zfs set mountpoint=legacy pool
Для просмотра свойств предназначен вариант get , например, их перечень можно получить так:
# zfs get all
Ряд свойств должен быть знаком тем, кто редактировал файл /etc/fstab . ZFS хранит их поближе к характеризуемым структурам, что бы «инструкция по использованию» была под рукой. Но это не мешает использовать и привычный подход.
Зачем нужна zfs, когда есть zpool?
Как правило, предпочтительно отделять данные пользователя в /home от системных. В ряде случаев требования к гибкости файловой иерархии повышены, а заранее предугадать количество разделов не представляется возможным. ZFS избавляет пользователя от вопросов «какие лучше выбрать размеры разделам?» и позволяет организовать в едином поле произвольное множество файловых систем, распределяя общий объём памяти по мере надобности, а при необходимости даёт возможность добавить новые физические носители.
В таких сценариях автоматически созданную ФС не используют непосредственно для хранения данных. Её рассматривают как родительскую: задают свойства, которые требуется унаследовать дочерним структурам, например:
# zfs set compression=lz4 pool # zfs set acltype=posixacl pool # zfs set xattr=xa pool
Заметим, что при указании некорректного значения свойства, в качестве подсказки будет выдан список возможных.
# zfs create pool/ROOT # zfs create pool/ROOT/rosa-1 # zfs create -o mountpoint=/home pool/home
Как видно, свойства можно задавать непосредственно при создании ФС, а не только менять позже. Отличная от legacy точка монтирования /home приведёт к тому, что pool/home окажется доступен по соответствующему пути в случае импорта, или команды zfs mount -a . Однако, нужно учитывать тонкость: свойство overlay по умолчанию off - если что-либо по заданному пути уже смонтировано, то оверлей создан не будет.
Помимо pool/ROOT/rosa-1 можно создать pool/ROOT/rosa-2 и установить два варианта ОС. Копию можно создавать не только привычным методом, но и используя механизм мгновенных снимков состояния zfs snapshot и клонирования zfs clone . С учётом таких сценариев, а так же возможности chroot , вместо mountpoint=/ удобнее выбрать legacy (и если читатель выполнил пример из предыдущего раздела, то оно таким и унаследовано от pool )
Запуск ОС Роса с ZFS
Осуществляется просто, если на диске создан отдельный раздел /boot для grub2 и ядер ОС. В таком случае в grub.cfg в качестве параметра ядра root следует указать путь к корневому разделу, возможны различные варианты:
Linux /vmlinuz-4.4.7-nrj-laptop-1rosa-x86_64 root=ZFS=pool/ROOT/rosa-1 ro linux /vmlinuz-4.4.7-nrj-laptop-1rosa-x86_64 root=zfs: ro zfs=pool/ROOT/rosa-1
С этой задачей справляется update-grub2 из официальных репозиториев, но в некоторых случаях требуется недавняя beta версия. Так же желательно установить и соответствующее свойство:
# zpool set bootfs=pool/ROOT/rosa-1
Для операционной системы , перенос которой на другие платформы вызвало всплеск диаметрально разных эмоций у разработчиков: от бурного восхищения и ликования, до прямо противоположного — раздражения и ярости.
Попробуем ознакомиться с точкой зрения каждой из сторон, а также в причинах существования столь полярных оценок этой файловой системы. Но, прежде чем мы это сделаем, давайте хотя бы в общих чертах ознакомимся с её особенностями и свойствами:
- 128-битная файловая система, что даёт возможность хранения практически неограниченных объёмов информации. На практике это значит, что ZFS теоретически может хранить объёмы информации, которые превышают сегодняшние технологические возможности, при условии использования текущего подхода к организации хранения данных;
- Очень большое внимание уделяется целостности и надежности хранения, как пользовательских данных, так и метаданных ФС, для этого используются продвинутые алгоритмы хэширования;
- Поддержка снапшотов (snapshot) и пулов хранения (storage pools), благодаря чему ZFS сочетает в себе возможности файловой системы и системы управления томами (новая концепция storage-пулов);
- Отсутствие необходимости в fsck благодаря этой ФС;
- Традиционно считается, что ZFS — это достаточно производительная файловая система. Впрочем, это утверждение иногда ставится под сомнение. Как минимум, конкретные цифры очень сильно зависят от типа задачи, на которой производится подобное сравнительное тестирование производительности;
- Возможности для избирательного сжатия и/или шифрования отдельных файлов или файловых систем;
- Поддержка автоматического распознавания и объединения (исключения) файлов-дубликатов;
- ZFS не поддерживает квоты. Вернее сказать, её поддержка квот несколько своеобразна: понятие «выделение квоты» значит в терминологии ZFS то, что вы ограничиваете размер создаваемой файловой системы. Дизайн системы таков, что каждому пользователю ZFS следует выделять свою собственную файловую систему со всеми сопутствующими ограничениями;
- Определенные проблемы создает не техническая особенность ФС — несовместимая с GPL лицензия на код (CDDL);
- Чтобы показать инновационность ZFS не только в области технических решений, приведу, как пример, возможность управлять основными возможностями ФС через веб-интерфейс;
- И , так как, повторюсь — ZFS чрезвычайно велик в своих возможностях и особенностях, и перечислить всех их здесь просто не представляется возможным.
Конечно, если смотреть на эти возможности по отдельности, то они во многом не новы и встречаются в том или ином виде в других файловых системах, но такой единый комплекс из приведенных возможностей впервые представлен только в ZFS, что и делает её столь уникальной и интересной на данный момент.
Если добавить сюда её относительно зрелый возраст и очень хорошее состояние в плане стабильности кода — становятся понятны те бури эмоций, которые вызвали новости о публикация её кода под открытой лицензией, а также портирование этой инновационной ФС на такие популярные ОС, как FreeBSD, Linux, MacOS X.
Что касается резко отрицательных откликов на эту, вне всяких сомнений, уже знаменитую файловую систему, то они сводятся в основном к следующим тезисам. Один из ведущих разработчиков Linux, кстати, ответственный за поддержку её дисковой подсистемы, (Andrew Morton), разразился гневными обличениями ZFS в «чудовищном нарушении уровней реализации».

Эндрю Мортан , ведущий разработчик дисковой подсистемы ядра Linux
Некоторые другие разработчики присоединилась к его обвинениям в «жутком дизайне» ZFS, и на данный момент можно констатировать, что Андрея Мортана в адрес ZFS — «ужасное нарушение уровней дизайна » и «необоснованная мешанина из кода » — стали уже своего рода интернет-мемами, на которые заочно уже попытались ответить разработчики из Oracle, Linux, RedHat, FreeBSD и других известных проектов.
В качества ответа на эти выпады, ведущего разработчика ZFS (Jeff Bonwick):
«Все эти обвинения в нарушении дизайна уровней реализации файловой системы, оттого, что ZFS комбинирует в себе одновременно функциональность файловой системы, менеджера томов и программного RAID-контроллера. Я полагаю, что ответ на эту претензию будет зависеть от того, что понимать под обвинением „нарушает дизайн уровней“.В процессе разработки ZFS мы установили, что стандартный дизайн абстрагированных уровней дискового стека провоцирует удивительное количество ненужной сложности и избыточной логики. В процессе рефакторинга мы пришли к мнению, что единственное решение проблемы — это фундаментальный пересмотр границ слоев и их отношений, — что делает все сразу намного более простым».
Какую бы позицию в отношении ZFS не занимали лично вы, следует признать как минимум одно: ZFS — это принципиально новая технология в индустрии файловых систем.
ZFS в порядке сжатия и дедупликации linux
каков порядок записи данных в файловую систему zfs в linux?
единственный конкретный документ я нашел на http://docs.oracle.com/cd/E36784_01/html/E36835/gkknx.html говорит: When a file is written, the data is compressed, encrypted, and the checksum is verified. Then, the data is deduplicated, if possible.
но если это правда, то дедупликация не будет дедупликации блоков, сжатых с различными алгоритмами сжатия.
Я тестировал mysqlf, и я считаю, что порядок следующий: dedup, compress, encrypt .
мой тест-настройка:
Zpool create tank /dev/sdb zfs create tank/lz4 zfs create tank/gzip9 zfs set compression=lz4 tank/lz4 zfs set compression=gzip-9 tank/gzip9 zfs set dedup=on tank
выход zfs list
NAME USED AVAIL REFER MOUNTPOINT tank 106K 19,3G 19K /tank tank/gzip9 19K 19,3G 19K /tank/gzip9 tank/lz4 19K 19,3G 19K /tank/lz4
сгенерируйте случайный файл с помощью dd if=/dev/urandom of=random.txt count=128K bs=1024
131072+0 Datensätze ein 131072+0 Datensätze aus 134217728 Bytes (134 MB) kopiert, 12,8786 s, 10,4 MB/s
вывод списка zpool в пустой пул:
NAME SIZE ALLOC FREE EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT tank 19,9G 134K 19,9G - 0% 0% 1.00x ONLINE -
затем скопируйте файлы в наборы данных с различными алгоритмами сжатия:
Cp random.txt /tank/lz4 cp random.txt /tank/gzip9
выход zfs list после копирования:
NAME USED AVAIL REFER MOUNTPOINT tank 257M 19,1G 19K /tank tank/gzip9 128M 19,1G 128M /tank/gzip9 tank/lz4 128M 19,1G 128M /tank/lz4
выход zpool list afer копирование:
NAME SIZE ALLOC FREE EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT tank 19,9G 129M 19,7G - 0% 0% 2.00x ONLINE -
коэффициент дедупликации 2.0 после копирование одного файла в разные наборы данных. На мой взгляд, это означает, что дедупликация выполняется на data -блоки перед сжатием и шифрованием.
пожалуйста, кто-нибудь может проверить, правильно ли это?
1 ответов
когда файл записывается, данные сжимаются, шифруются, и контрольная сумма проверяется. Затем данные дедуплицируются, если это возможно.
мое предположение со случайным файлом было неверным. Кажется, что ZFS прерывает сжатие, если не может достичь определенного минимального коэффициента сжатия.
другая определенная вещь, котор нужно заметить что представление LZ4 на несжимаемых данных очень высоко. Это достигается путем включения механизма "раннего прерывания", который срабатывает, если LZ4 не может соответствовать ожидаемому минимальному коэффициенту сжатия (12,5% на ZFS).
В мире *nix-систем все более популярными становятся файловые системы ZFS и Btrfs. Популярность эта вполне заслуженна - в отличие от своих предшественников, они лишены некоторых проблем и имеют множество неоспоримых достоинств. А не так давно им присвоен статус стабильных. Все это и побудило написать данную статью.
WARNING!
Некоторые описываемые здесь команды способны необратимо уничтожить твои данные. Трижды проверяй введенное, прежде чем нажимать Enter.
Пожалуй, прежде чем перейти к практике, нужно дать некоторые пояснения, что собой представляют файловые системы нового поколения. Начну с ZFS. Эта ФС была разработана для Solaris и в настоящее время, поскольку Oracle закрыла исходный код, форкнута в версию OpenZFS. В дальнейшем под ZFS будет подразумеваться именно форк. Вот лишь некоторые из ключевых особенностей ZFS:
- огромный до невообразимости максимальный размер ФС;
- пулы хранения, которые позволяют объединять несколько разных устройств;
- контрольные суммы уровня файловой системы, при этом есть возможность выбирать алгоритм;
- основана на принципе COW - новые данные не перезаписывают старые, а размещаются в других блоках, что открывает такие возможности, как снапшоты и дедупликация данных;
- сжатие данных на лету - как и в случае с контрольными суммами, поддерживается несколько алгоритмов;
- возможность управлять файловой системой без перезагрузки.
Btrfs начала разрабатываться в пику ZFS компанией Oracle - еще до покупки Sun. Я не буду описывать ее особенности - они в ZFS и Btrfs, в общем-то, схожи. Отличия же от ZFS таковы:
- поддержка версий файлов (в терминологии Btrfs называемых поколениями) - есть возможность просмотреть список файлов, которые изменялись с момента создания снапшота;
- отсутствие поддержки zvol, виртуальных блочных устройств, на которых можно разместить, к примеру, раздел подкачки, - но данное отсутствие вполне компенсируется loopback-устройствами.
Знакомство с ZFSonLinux
Для установки ZFSonLinux потребуется 64-разрядный процессор (можно и 32, но разработчики не обещают стабильности работы в таком случае) и, соответственно, 64-разрядный дистрибутив с ядром не ниже 2.6.26 - я использовал Ubuntu 13.10. Памяти тоже должно быть достаточно - не менее 2 Гб. Предполагается, что основные пакеты, необходимые для сборки и компиляции модулей и ядра, уже установлены. Накатываем дополнительные пакеты и качаем нужные тарболлы:
$ sudo apt-get install alien zlib1g-dev uuid-dev libblkid-dev libselinux-dev parted lsscsi wget $ mkdir zfs && cd $_ $ wget http://bit.ly/18CpniI $ wget http://bit.ly/1cEzO0V
Распаковываем оба архива, но сперва собираем SPL - слой совместимости с Solaris, а уж затем собственно ZFS. Отмечу, что, поскольку мы ставим свежайшую версию ZFSonLinux, DKMS (механизм, позволяющий автоматически перестраивать текущие модули ядра с драйверами устройств после обновления версии ядра) недоступен, и в случае обновления ядра придется собирать пакеты заново вручную.
$ tar -xzf spl-0.6.2.tar.gz $ tar -xzf zfs-0.6.2.tar.gz $ cd spl-0.6.2 $ ./configure $ make deb-utils deb-kmod
Прежде чем компилировать ZFS, нужно поставить хидеры, заодно поставим и остальные свежесобранные пакеты:
$ sudo dpkg -i *.deb
Наконец, собираем и ставим ZFS:
$ cd ../zfs-0.6.2 $ ./configure $ make deb-utils deb-kmod $ sudo dpkg -i *.deb

Перенос корневой ФС на ZFS с шифрованием и созданием RAIDZ
Предположим, ты хочешь получить безопасную, зашифрованную, но в то же время отказоустойчивую файловую систему. В случае с классическими ФС старого поколения тебе пришлось бы выбирать между шифрованием и отказоустойчивостью, поскольку эти вещи несколько несовместимы. В ZFS, однако, существует возможность «склеить» их между собой. Современная проприетарная реализация этой ФС поддерживает шифрование. Открытая реализация с версией пула 28 это не поддерживает - но ничто не мешает с помощью cryptsetup создать том (или несколько томов) LUKS и уже поверх них разворачивать пул. Что до отказоустойчивости ZFS, поддерживается создание мультидисковых массивов. Технология эта называется RAIDZ. Различные ее варианты позволяют пережить отказ от одного до трех дисков, и она, в силу некоторых особенностей ZFS, свободна от одного из фундаментальных недостатков традиционных stripe + parity RAID-массивов - write hole (ситуация с RAID 5 / RAID 6, когда при активных операциях записи и отключении питания данные на дисках в итоге отличаются).
INFO
Шифрование замедляет работу с данными. Не стоит его использовать на старых компьютерах.
Конечно, проще всего, если у тебя не стоит никакой системы - в этом случае заморачиваться придется меньше. Но живем мы не в идеальном мире, поэтому расскажу о том, как перенести уже установленную систему без раздела /boot на массив RAIDZ поверх томов LUKS.
Перво-наперво нужно создать сам этот раздел - без него перенос будет невозможен, поскольку система банально не загрузится. Предположим для простоты, что на диске имеется единственный раздел с Ubuntu, а хотим мы создать RAIDZ первого уровня (аналог RAID 5, для него требуется минимум три устройства, RAIDZ же больших уровней в домашних условиях смысла делать я не вижу). Создаем с помощью предпочитаемого редактора разделов два раздела - один размером 256–512 Мб, где и будет размещен /boot , и еще один, с размером не меньше текущего корневого, причем последнюю процедуру повторяем на всех трех жестких дисках. Перечитаем таблицу разделов командой
# partprobe /dev/disk/by-id/ata-VBOX_HARDDISK_VB203f5b52-a7ff5309
и создадим файловую систему (ext3) на разделе поменьше:
# mke2fs -j /dev/disk/by-id/ata-VBOX_HARDDISK_VB203f5b52-a7ff5309-part2 -L boot
Разумеется, в твоем случае идентификаторы жестких дисков будут другими. Вслед за этим нужно зашифровать раздел, на котором будет находиться том LUKS, и повторить эту процедуру для всех остальных разделов, на которых в конечном счете будет находиться массив RAIDZ:
# cryptsetup -h=sha512 -c=aes-cbc-essiv:sha256 -s=256 -y luksFormat /dev/disk/by-id/ata-VBOX_HARDDISK_VB203f5b52-a7ff5309-part3 # cryptsetup -h=sha512 -c=aes-cbc-essiv:sha256 -s=256 -y luksFormat /dev/disk/by-id/ata-VBOX_HARDDISK_VB2fdd0cb1-d6302c80-part1 # cryptsetup -h=sha512 -c=aes-cbc-essiv:sha256 -s=256 -y luksFormat /dev/disk/by-id/ata-VBOX_HARDDISK_VB781404e0-0dba6250-part1
Подключаем зашифрованные тома:
# cryptsetup luksOpen /dev/disk/by-id/ata-VBOX_HARDDISK_VB203f5b52-a7ff5309-part3 crypto0 # cryptsetup luksOpen /dev/disk/by-id/ata-VBOX_HARDDISK_VB2fdd0cb1-d6302c80-part1 crypto1 # cryptsetup luksOpen /dev/disk/by-id/ata-VBOX_HARDDISK_VB781404e0-0dba6250-part1 crypto2
И создаем пул ZFS:
# zpool create -o ashift=12 zroot raidz dm-name-crypto0 dm-name-crypto1 dm-name-crypto2
Следом создаем две вложенные друг в друга файловые системы:
# zfs create zroot/ROOT # zfs create zroot/ROOT/ubuntu-1310-root
Отмонтируем все файловые системы ZFS и устанавливаем некоторые свойства ФС и пула:
# zfs umount -a # zfs set mountpoint=/ zroot/ROOT/ubuntu-1310-root # zpool set bootfs=zroot/ROOT/ubuntu-1310-root zroot
Наконец, экспортируем пул:
# zpool export zroot


Перенос и конфигурация системы
Сначала копируем каталог /boot на нешифрованный раздел, чтобы следом установить туда загрузчик:
# mkdir /mnt/boot # mount /dev/disk/by-label/boot /mnt/boot # cp -r /boot/* /mnt/boot/ # umount /mnt/boot
После этого перенесем grub на отдельный раздел /boot , для чего добавим в /etc/fstab cтрочку
# <...> LABEL=boot /boot ext3 errors=remount-ro 0 0
Монтируем и перегенерируем конфиг grub:
# grub-mkconfig -o /boot/grub/grub.cfg
Для проверки перезагружаемся. Если все нормально, удаляем старое содержимое каталога /boot , не забыв предварительно отмонтировать раздел.
Пришло время клонировать Ubuntu. Весь процесс клонирования описан в полной версии статьи, которую можно найти на сайте ][, здесь же затрону некоторые тонкости, относящиеся к ZFS. Для нормальной загрузки с пула ZFS нужны некоторые скрипты initramfs. К счастью, изобретать их не нужно - они лежат на GitHub. Скачиваем репозиторий (все действия производим в chroot):
# git clone http://bit.ly/1esoc8i
И копируем файлы в необходимые места. Я внес единственную правку: вместо пула rpool поставил zroot. Теперь нужно записать hostid в файл /etc/hostid . Это нужно сделать из-за того, что ZFS портирована с Solaris, и слой совместимости требует его наличия:
# hostid >/etc/hostid
Наконец, нужно сгенерировать initramfs. Ни в коем случае не используй update-initramfs . Он перезаписывает существующий файл, и, если возникнут трудности, загрузиться с нормальной системы будет проблематично. Вместо него используй команду
# mkinitramfs -o /boot/initrd.img-$(uname -r)-crypto-zfs
Раздел /boot должен быть подмонтирован.
Затем нужно добавить пункт меню в grub. По причине достаточно хитрой конфигурации (еще бы: три криптотома, поверх которых расположена не совсем типичная для Linux файловая система) в chroot это сделать не получилось, поэтому выходим из него в основную (пока еще) систему и добавляем примерно такие строчки:
# vi /etc/grub.d/40_custom menuentry "Ubuntu crypto ZFS" { # <...> linux /vmlinuz-3.11.0-14-generic boot=zfs rpool=zroot initrd /initrd.img-3.11.0-14-generic-crypto-zfs }
Запускаем update-grub , перезагружаемся, выбираем новый пункт меню и радуемся.

Тюнинг ZFS и полезные трюки c Btrfs
В большинстве случаев домашние пользователи не настраивают свои ФС. Однако параметры по умолчанию ZFS отнюдь не всегда подходят для применения в домашних условиях. Существуют также довольно интересные возможности, использование которых требует определенных навыков работы с данной файловой системой. Далее я опишу как тонкую подстройку ZFS под домашние нужды, так и эти возможности.
В случае же использования Btrfs никаких особых проблем не наблюдается. Тем не менее какие-то тонкости все же имеют место - в особенности если есть желание не просто «поставить и забыть», а задействовать новые возможности. О некоторых из них я и расскажу ниже.
Отключение изменения времени доступа к файлам и оптимизация для SSD-накопителей
Как известно, в *nix-системах каждый раз при обращении к файлам время доступа к ним меняется. Это всякий раз провоцирует запись на носитель. Если ты работаешь одновременно с множеством файлов или у тебя SSD-накопитель, это может оказаться неприемлемым. В классических файловых системах для отключения записи atime нужно было добавить параметр noatime в опции команды mount или в /etc/fstab . В ZFS же для отключения используется следующая команда (конечно, в твоем случае ФС может быть другой):
# zfs set atime=off zroot/ROOT/ubuntu-1310-root
В Btrfs, помимо вышеупомянутой опции noatime, имеется опция ssd и более оптимизирующая ssd_spread. Первая из них начиная с ядра 2.6.31, как правило, устанавливается автоматически, вторая предназначена для дешевых SSD-накопителей (ускоряет их работу).
ZFS - дублирование файлов
При работе с очень важными данными порой возникает пугающая мысль, что отключат электроэнергию или выйдет из строя один из жестких дисков. Первое в российских условиях очень даже возможно, а второе хоть и маловероятно, но тоже случается. К счастью, разработчики ZFS, по-видимому, сталкивались с подобным не раз и добавили опцию дублирования данных. Файлы при этом, если возможно, размещаются на независимых дисках. Предположим, у тебя есть ФС zroot/HOME/home-1310 . Для установки флага дублирования набери следующую команду:
# zfs set copies=2 zroot/HOME/home-1310
Более того, если двух копий покажется недостаточно, можно указать цифру 3. В этом случае выполняется тройное резервирование и, если откажут два жестких диска из трех, на которых лежат эти копии, ZFS все равно восстановит их.
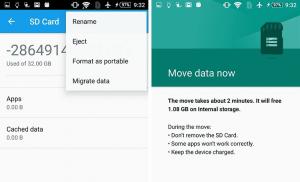
Отключение автомонтирования в ZFS
При подключении пула по умолчанию автоматом монтируются все вложенные файловые системы. Это может вызвать некоторый конфуз, поскольку, например, в случае с приведенной выше конфигурацией пользователю не нужен доступ ни к zroot , ни к zroot/ROOT . Существует возможность отключить автомонтирование с помощью двух следующих команд (для данного случая):
# zfs set canmount=noauto zroot/ROOT # zfs set canmount=noauto zroot
Сжатие данных
ZFS поддерживает также и сжатие данных. На шифрованных томах это имеет смысл разве что для увеличения энтропии (и то не факт), но вообще для медленных носителей сжатие позволяет повысить производительность и может достаточно ощутимо сэкономить место на диске. В то же время сейчас, когда емкость винчестеров уже измеряется терабайтами, экономить место вряд ли кому-то особо нужно, а на производительности и расходе оперативной памяти это сказывается больше. Если же тебе это нужно, включить его можно следующим образом:
# zfs set compression=on zroot/ROOT/var-log
В Btrfs для включения сжатия нужно поставить опцию compress в /etc/fstab .
Автоматическое создание снапшотов в ZFS
Как известно, ZFS позволяет создавать снапшоты. Ручками, однако, их создавать лениво, да и есть вероятность попросту забыть об этом. В Solaris для автоматизации этой процедуры имеется служба Time Slider, но она - вот незадача! - хоть и использует функции ZFS, в ее состав не входит, поэтому в ZFSonLinux ее нет. Но огорчаться не стоит: имеется скрипт для автоматического их создания и для Linux. Скачаем его и установим нужные права:
# wget -O /usr/local/sbin/zfs-auto-snapshot.sh http://bit.ly/1hqcw3r # chmod +x /usr/local/sbin/zfs-auto-snapshot.sh
Изменим сперва префикс для снапшотов, поскольку по умолчанию он не особо «говорящий». Для этого изменим в скрипте параметр opt_prefix с zfs-auto-snap на snapshot . Затем установим некоторые переменные файловой системы:
# zfs set com.sun:auto-snapshot=true zroot/ROOT/ubuntu-1310-root # zfs set snapdir=visible zroot/ROOT/ubuntu-1310-root
Первый параметр нужен для скрипта, второй же открывает прямой доступ к снапшотам, что тоже нужно для скрипта.
Теперь можно уже создавать скрипт для cron (/etc/cron.daily/autosnap). Рассмотрим случай, когда нужно создавать снапшоты каждый день и хранить их в течение месяца:
#!/bin/bash ZFS_FILESYS="zroot/ROOT/ubuntu-1310-root" /usr/local/sbin/zfs-auto-snapshot.sh --quiet --syslog --label=daily --keep=31 "$ZFS_FILESYS"
Для просмотра созданных снапшотов используй команду zfs list -t snapshot , а для восстановления состояния - zfs rollback имя_снапшота.
ZFS - комплексный пример
Ниже будут приведены команды, создающие несколько ФС в пуле для разных целей и демонстрирующие гибкость ZFS.
# zfs create -o compression=on -o mountpoint=/usr zroot/ROOT/usr # zfs create -o compression=on -o setuid=off -o mountpoint=/usr/local /zroot/ROOT/usr-local # zfs create -o compression=on -o exec=off -o setuid=off -o mountpoint=/var/crash zroot/ROOT/var-crash # zfs create -o exec=off -o setuid=off -o mountpoint=/var/db zroot/ROOT/var-db # zfs create -o compression=on -o exec=off -o setuid=off -o mountpoint=/var/log zroot/ROOT/var-log # zfs create -o compression=gzip -o exec=off -o setuid=off -o mountpoint=/var/mail zroot/ROOT/var-mail # zfs create -o exec=off -o setuid=off -o mountpoint=/var/run zroot/ROOT/var-run # zfs create -o exec=off -o setuid=off -o copies=2 -o mountpoint=/home zroot/HOME/home # zfs create -o exec=off -o setuid=off -o copies=3 -o mountpoint=/home/rom zroot/HOME/home-rom
Дефрагментация Btrfs
Дефрагментация в Btrfs не столь уж необходима, но в отдельных случаях позволяет освободить занятое пространство. Она может быть проведена только на смонтированной системе. Замечу, что доступ к данным во время дефрагментации сохраняется - как на чтение, так и на запись. Для запуска процедуры дефрагментации используй следующую команду:
# btrfs filesystem defrag /
На старых ядрах эта процедура удаляла все COW-копии, такие как снапшоты и дедуплицированные данные, так что, если ты их используешь на ядрах старше 2.6.37, дефрагментация тебе только навредит.
RAID на Btrfs
Как и в случае с ZFS, Btrfs поддерживает многотомные массивы, но в отличие от ZFS называются они классически. На данный момент, однако, поддерживаются только RAID 0, RAID 1 и их комбинация, RAID 5 по-прежнему на этапе альфа-тестирования. Для создания нового массива RAID 10 попросту используй такую команду (с твоими устройствами):
# mkfs.btrfs /dev/sda1 /dev/sdb1 /dev/sdc1 /dev/sdd1
Ну а если нужно сконвертировать существующую ФС в RAID, то и для этого есть команды:
# btrfs device add /dev/sdb1 /dev/sdc1 /dev/sdd1 / # btrfs balance start -dconvert=raid10 -mconvert=raid10 /
Первая команда добавляет устройства к файловой системе, вторая же как раз и перебалансирует все данные и метаданные для преобразования этого набора томов в массив RAID 10.
Снапшоты Btrfs
Естественно, Btrfs поддерживает снапшоты - причем помимо обычных снапшотов доступны снапшоты с возможностью записи (более того, они и создаются по умолчанию). Для создания снапшотов используется следующая команда:
# btrfs subvol snap -r / /.snapshots/2013-12-16-17-41
Подробнее о создании снапшотов, как ручном, так и автоматическом, можно прочитать в статье «Подушка безопасности», опубликованной в апрельском номере ][ за 2013 год. Здесь же я расскажу, как при наличии снапшота отследить, какие файлы изменились с момента его создания. Для этого в Btrfs есть так называемое поколение файлов. Возможность эта используется для внутренних целей, но есть команда, позволяющая смотреть список последних изменений - ею и воспользуемся. Сначала узнаем текущее поколение файлов:
# btrfs subvol find-new / 99999999
Если такого поколения нет (в чем можно практически не сомневаться), выведется последнее. Теперь эту же самую команду выполним над снапшотом:
# btrfs subvol find-new /.snapshots/2013-12-17-14-28 99999999
Если поколения будут отличаться, а они будут, то смотрим, какие же файлы изменялись со времени создания снапшота. В моем случае команда была следующей:
# btrfs subvol find-new / 96 | awk "{ print $17 }" | sort | uniq
NILFS2 - еще одна файловая система с поддержкой COW
Начиная с ядра 2.6.30 в Linux появилась поддержка еще одной ФС - NILFS2. Аббревиатура эта расшифровывается как new implementation of a log-structured file system. Основная особенность данной ФС заключается в том, что раз в несколько секунд в ней автоматически создаются чек-пойнты - примерный аналог снапшотов с одним отличием: спустя какое-то время они удаляются сборщиком мусора. Пользователь, тем не менее, может преобразовать как чек-пойнт в снапшот, в результате чего для сборщика мусора он становится невидимым, так и наоборот. Таким образом, NILFS2 можно рассматривать как своеобразную «Википедию», где фиксируются любые изменения. Из-за этой особенности - писать любые новые данные не поверх существующих, а в новые блоки - она прекрасно подходит для SSD-накопителей, где, как известно, перезапись данных не приветствуется.
Да, NILFS2 не настолько известна, как ZFS или Btrfs. Но в некоторых случаях ее применение будет более оправданным.
Заключение
Может быть, я покажусь субъективным, но ZFS, если ее сравнивать с Btrfs, выигрывает. Во-первых, некоторые возможности Btrfs до сих пор находятся в зачаточном состоянии, несмотря на то, что ей уже более пяти лет. Во-вторых, ZFS, при прочих равных условиях, более обкатана. И в-третьих, как просто инструментов для работы с ZFS, так и ее возможностей больше.
С другой стороны, как бы ни была хороша ZFS, по лицензионным соображениям она вряд ли когда-нибудь будет включена в mainline kernel. Так что, если не появится какой-нибудь еще конкурент, придется пользоваться Btrfs.
Facebook и Btrfs
В ноябре 2013 года лидер команды разработчиков Btrfs Крис Мейсон перешел на работу в Facebook. Это же сделал и Джозеф Бацик, мейнтейнер ветки btrfs-next. Они вошли в состав отдела компании, специализирующегося на низкоуровневых разработках, где и занимаются ныне ядром Linux - в частности, работают над Btrfs. Разработчики заявили также, что Facebook заинтересована в развитии Btrfs, так что причин волноваться у сообщества нет решительно никаких.
(оригинал)
Тюнинг
Вопросы новичка по zfs
Каковы аппаратные требования для zfs?
Минимальные, чтобы только включилось - 512 М памяти и 32 бит процессор. Минимальные рабочие - 64 бит процессор (напр двух ядерный атом) и 1Гб памяти. Желательно - процессоры Sandy или Ivy Bridge, можно младшие. Памяти чем больше, тем лучше, но в домашних условиях больше 8 Гб вряд ли нужно. (Не забудьте сделать тюнинг, если памяти много, см ниже.) Часто приходится слышать рекомендацию “гигабайт памяти на терабайт массива”. Но пока ни в одном из заслуживающих доверия источников этой рекомендации найти не удалось. Так что, возможно, это городская легенда. В идеале и в production память ECC, но у подавляющего большинства камрадов память обычная. Прим. Для режима дедупликации требуются очень большие, иногда непредсказуемо большие, объемы памяти, см ниже.
Попытки использования в домашних условиях SSD для кеширования как чтения, так и записи не дали заметных позитивных результатов. MikeMac
Какие есть варианты массивов (пулов) zfs?
Массив строится как набор виртуальных устройств (vdev). Часто пул состоит из одного vdev. Виды vdev (Прим. для краткости говорим, что vdev состоят из дисков, хотя это могут быть и разделы дисков и файлы и пр.)
- stripe - страйп, нечто среднее между RAID0 и JBOD. Не имеет избыточности, вся информация теряется при смерти любого из дисков.
- mirror - зеркало, примерный аналог RAID1. Каждый диск зеркала содержит полную копию всей информации. Выдерживает смерть одного любого диска. Возможно и тройное зеркало.
- raidz1 - примерный аналог RAID5, требует минимум 3 дисков, объем одного диска уходит на избыточность. Выдерживает смерть одного любого диска.
- raidz2 - примерный аналог RAID6, требует минимум 4 диска, объем двух дисков уходит на избыточность. Выдерживает смерть двух любых дисков.
- raidz3 - требует минимум 5 дисков, объем трёх дисков уходит на избыточность. Выдерживает смерть трёх любых дисков.
Если в пул входит несколько vdev, то они объединяются в страйп из vdev. Так можно сделать примерный аналог RAID10 (страйп из зеркал) или RAID60 (страйп из raidz2). Входящие в пул vdev могут иметь разный размер, но строго рекомендуются одного типа (хотя технически возможно собрать пул из разных типов vdev). Например, не рекомендуется объединять в пул raidz1 и страйп из-за падения надёжности. MikeMac
Каковы сравнительные достоинства и недостатки различных типов vdev?
- stripe
- + используется всё пространство дисков; увеличение производительности аналогично RAID0
- - низкая надежность, вся информация теряется при смерти любого из дисков.
- mirror
- + высокая производительность и надежность
- - половина объема уходит на избыточность (2/3 для тройного зеркала)
- raidz1
- + Экономное использование дискового пространства при обеспечении избыточности
- - некоторое снижение производительности по сравнению с зеркалом; при смерти одного из дисков до окончания перестроения на новый диск имеем страйп в смысле надежности
- raidz2
- + высокая надежность, расчёты показывают, что более высокая, чем у зеркала - если вы и потеряете массив, то не из-за выхода дисков из строя, а из-за проблем с другими компонентами
- - два диска уходят на избыточность
- raidz3
- + параноидальная надежность, излишняя практически всегда
- - три диска на избыточность. MikeMac
И какой вариант мне предпочесть?
- stripe для малоценной или легко восстанавливаемой информации (оцените и затраты своего времени)
- mirror для высокой нагрузки случайного чтения/записи
- raidz1 как базовый вариант для файлопомойки
- raidz2 как премиум вариант
NB: Никакой RAID не заменяет Backup. Важная, невосстановимая информация должна быть сохранена куда-то вовне. MikeMac
Подробнее о vdev
Сжатие включать?
Oleg Pyzhov : какие разделы сжимать, какие нет определил опытным путем. Проц у меня атомный поэтому без вариантов тип сжатия lzjb
- storage1/system 6,74G compressratio 1.71x (тут лежат скрипты, а также каталоги для FreeBSD: /usr/src, /usr/obj, /usr/ports)
- storage1/soft 61,6G compressratio 1.17x (тут дистрибьютивы)
- storage1/document 302G compressratio 1.16x (тут много мелких файлов: DWG,DOC,XLS, JPG)
- storage1/timemachine сжатие не испольщую, тк неэффективно.. MacOSX и так походу сжимает свой Backup)
- storage1/media не сжимаю, тк неэффективно
Sergei V. Sh : размеры датасета с кучей фото
- 93.2G (ashift=9 compresion=on)
- 95.0G (ashift=9 compresion=off)
- 94.5G (ashift=12 compresion=on)
- 96.1G (ashift=12 compresion=off)
Как переименовать пул?
zpool export poolname zpool import poolname newname
Как удалить файл, если нет места на диске с ZFS
dd if = /dev/null of = file.avi rm file.avi
UPD от MikeMac На практике оказалось, что первым пунктом следует проверить наличие снапшотов
zfs list -t snapshot
Если снапшоты есть, то их следует удалять (http://docs.oracle.com/cd/E19253-01/819-5461/gbcya/index.html), начиная с наиболее древних, пока не появится место (или пока не будут удалены все).
Если же проводить операцию по усечению файла как выше - то в случае наличия его копии в снапшоте операция не высвободит места.
Кроме того, практика показывает что усечение файла лучше проводить над небольшими файлами.
Как узнать точный размеры пула?
- Как определить полный объем пула, доступный пользователю (т.е. за вычетом ушедшего на избыточность)?
USED - объем занятого пространства AVAIL - сколько осталось
- Сиди складывай USED + AVAIL?
- в байтах для датасета zpool/var:
zfs get -Hp -o value avail,used zpool/var | awk "{ s+=$1; } END { print s; }"
- в терабайтах:
zfs get -Hp -o value avail,used zpool/var | awk "{ s+=$1; } END { printf "%.3f Tb.\n", s/(1048576*1048576); }"
От WearWolf .
Заменил все диски на бОльшие, но размер пула не изменился, что делать?
Наиболее простой для новичка способ - перезагрузить систему. Если это не помогает
zpool online -e <имя пула> <имя любого диска из этого пула>
Если задать автоувеличение при помощи команды
zpool set autoexpand = on <имя пула>
Пул будет сам вырастать. Sergei V. Sh
Автоувеличение пула не работало перепробовал все трюки - включение autoexpand=on , экспорт-импорт, ребут импорт пула был невозможен пока не деинсталировал VirtualBox - расположен на пуле и при попытке принудительного экспорта просто уводит весь нас в ребут.
Данная рекоммендация, по всей видимости, не актуальна для новых версий ZoL.
Для настоящих знатоков извращений:)
Q.
Купить разом все хдд не имею возможности, а ухудшать конфиг не хочу
A.
мой случай… я сделал себе 8+2 (raidz2 из 10 дисков) - но дисков сразу не имею
Q.
А какими командами FreeBSD поделить 2T диск на половинки для этого?
A.
например, так
Q.
имею raidz1 на 2T дисках. Заменить каждый на 4T - ноль проблем. Но в выхлопе остается несколько шт 2T дисков. Печалька.
A.