Структурированный язык запросов – SQL: история, стандарты, основные операторы языка. Основные операторы языка SQL. Интерактивный SQL
Язык структурированных запросов Structure Query Language (SQL) был создан в результате разработки реляционной модели данных и в настоящее время является фактическим стандартом языка реляционных СУБД. Язык SQL сегодня поддерживается огромным количеством СУБД различных типов.
Название языка SQL произносится обычно по буквам «эс-кью-эль». Иногда используют мнемоническое имя «See-Quel».
Язык SQL предоставляет пользователю (при минимальных усилиях с его стороны) следующие возможности:
Создавать базы данных и таблицы с полным описанием их структуры
Выполнять основные операции манипулирования данными: вставка, изменение, удаление данных
Выполнять как простые, так и сложные запросы.
Язык SQL является реляционно полным.
Структура и синтаксис его команд достаточно просты, а сам язык является универсальным, т. е. синтаксис и структура его команд не меняется при переходе от одной СУБД к другой.
Язык SQL имеет два основных компонента:
Язык DDL (Data Definition Language) для определения структур базы данных и управления доступом к данным
Язык DML (Data Manipulation Language), предназначенный для выборки и обновления данных.
Язык SQL является непроцедурным, т. е. при его использовании необходимо указывать то, какая информация должна быть получена, а не то, как ее можно получить. Команды языка SQL представляют собой обычные слова английского языка (SELECT, INSERT и др.). Рассмотрим вначале операторы SQL DML:
SELECT - выборка данных из базы
INSERT - вставка данных в таблицу
UPDATE - обновление данных в таблице
DELETE - удаление данных из таблицы
Оператор SELECT
Оператор выборки SELECT выполняет действия, эквивалентные следующим операциям реляционной алгебры: выборка, проекция и соединение.
Простейший SQL-запрос с его использованием выглядит следующим образом:
SELECT col_name FROM tbl
После ключевого слова select следует список столбцов, разделенных запятыми, данные которых будут возвращены в результате запроса. Ключевое слово from, указывает, из какой таблицы (или представления) извлекаются данные.
Результатом запроса select всегда является таблица, которая называется результирующей таблицей. Более того, результаты запроса, выполненного при помощи оператора select, могут быть использованы для создания новой таблицы. Если результаты двух запросов к разным таблицам имеют одинаковый формат, их можно объединить в одну таблицу. Также таблица, полученная в результате запроса, может стать предметом дальнейших запросов.
Для выборки всех столбцов и всех строк таблицы достаточно сделать запрос SELECT * FROM tbl;
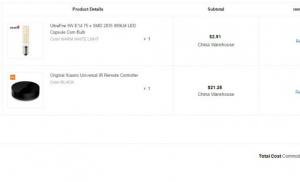
Рассмотрим таблицу Product, содержащую сведения о цене на различные виды продукции:
Результатом запроса
SELECT * FROM Product;
будет вся таблица Product.
Выбрать конкретные столбцы таблицы можно с помощью запроса
SELECT col1, col2, … , coln FROM tbl;
Так, результатом запроса
SELECT Type, Price FROM Product;
будет таблица
К списку столбцов в операторе select прибегают и в том случае, если необходимо изменить порядок следования столбов в результирующей таблице:
Для того чтобы выбрать лишь те строки таблицы, которые удовлетворяют некоторым ограничениям, используется специальное ключевое слово where, после которого следует логическое условие. Если запись удовлетворяет такому условию, она попадает в результат. В противном случае такая запись отбрасывается.
Например, выбор тех товаров из таблицы Product, цена которых удовлетворяет условию Price <3200, можно осуществить, используя запрос
SELECT * FROM Product where Price <3200;
Его результат:
Условие может быть составным и объединяться при помощи логических операторов NOT , AND, OR, XOR, например: where id_ Price>500 AND Price<3500. Допускается также использование выражений в условии: where Price>(1+1) и строковых констант: where name= "автовесы".
Применение конструкции BETWEEN var1 AND var2 позволяет проверить, попадают ли значения какого-либо выражения в интервал от var1 до var2 (включая эти значения):
SELECT * FROM Product where Price BETWEEN 3000 AND 3500;
По аналогии с оператором NOT BETWEEN существует оператор NOT IN.
Имена столбцов, указанные в предложении SELECT, можно переименовать. Для этого используется ключевое слово AS, которое, впрочем, можно опустить, т. к. неявно подразумевается. Например, запрос
SELECT Type AS model, Type_id AS num FROM Product where Type_id =3
вернет (имена псевдонимов следует записывать без кавычек):
Оператор LIKE предназначен для сравнения строки с образцом:
SELECT * FROM tbl where col_name LIKE "abc"
Этот запрос возвращает лишь те записи, которые содержат в столбце col_name строковое значение abc.
В образце разрешается использовать два трафаретных символа: "_" и "%". Первый из них заменяет в шаблоне один произвольный символ, а второй - последовательность произвольных символов. Так, "abc%" соответствует любой строке, начинающейся на abc, "abc_" - строке из 4-х символов, начинающейся на abc, "%z" - произвольной строке, заканчивающейся на z, и, наконец, "%z%" - последовательности символов, содержащих z.
Найти все записи таблицы Product, в которых значение Type начинается с буквы "a" можно так:
SELECT * FROM Product where Type LIKE "а%";
|
автовесы |
Если искомая строка содержит трафаретный символ, то следует задать управляющий символ в предложении ESCAPE. Этот управляющий символ должен использоваться в образце перед трафаретным символом, сообщая о том, что последний следует трактовать как обычный символ. Например, если в некотором поле следует отыскать все значения, содержащие символ "_", то шаблон "%_%" приведет к тому, что будут возвращены все записи из таблицы. В данном случае шаблон следует записать следующим образом:
"%|_%" ESCAPE "|"
Для проверки значения на соответствие строке "20%" можно воспользоваться таким оператором:
LIKE "20#%" ESCAPE "#"
Оператор IS NULL позволяет проверить отсутствие (наличие) NULL-значения в полях таблицы. Использование в этих случаях обычных операторов сравнения может привести к неверным результатам, так как сравнение со значением NULL дает результат UNKNOWN (неизвестно). Таким образом, условие отбора должно выглядеть так:
where col_name IS NULL, вместо where col_name=NULL.
Результат выборки по умолчанию возвращает записи, расположенные в том же порядке, в котором они хранятся в базе данных. Если требуется отсортировать записи по одному из столбцов, необходимо применить конструкцию ORDER BY, после которой указывается имя этого столбца:
SELECT * FROM tbl ORDER BY col_name;
В результате этого запроса записи будут возвращены в порядке возрастания значения атрибута col_name.
Сортировку записей можно производить и по нескольким столбцам. Для этого их названия надо указать после ORDER BY через запятую:
SELECT * FROM tbl ORDER BY col_name1, col_name2.
Записи будут отсортированы по полю col_name1; если встречается несколько записей с совпадающим значением в колонке col_name1, то они будут отсортированы по полю col_name2.
Если требуется отсортировать записи в обратном порядке (например, по убыванию даты), требуется указать ORDER BY col_name DESC.
Для прямой сортировки существует ключевое слово ASC, которое принято в качестве значения по умолчанию.
Если результат выборки содержит сотни и тысячи записей, их вывод и обработка занимают значительное время.
Поэтому информацию часто разбивают на страницы и предоставляют ее пользователю порциями. Постраничная навигация используется при помощи ключевого слова limit, за которым следует число выводимых записей. В следующем запросе извлекаются первые 10 записей, при этом одновременно осуществляется обратная сортировка по полю col_name1:
SELECT * FROM tbl ORDER BY col_name1 DESC LIMIT 10
Для того чтобы извлечь следующие 10 записей, используется ключевое слово limit с двумя значениями: первое указывает позицию, начиная с которой необходимо вывести результат, а вторая -- количество извлекаемых записей:
SELECT * FROM tbl ORDER BY col_name1 DESC LIMIT 10,10
Для извлечения следующих 10 записей необходимо использовать конструкцию LIMIT 20, 10.
Синтаксис оператора SELECT имеет следующий вид:SELECT <список атрибутов>/* FROM <список таблиц>
В квадратных скобках указываются элементы, которые могут в запросе отсутствовать.
Выдать список всех студентов .
SELECT * FROM student
SELECT id_st, surname FROM student
Заметим, что если добавить к данному запросу предложение ORDER BY surname, то список будет упорядочен по фамилии. По умолчанию подразумевается, что сортировка производится по возрастанию. Если необходимо упорядочение по убыванию, после имени атрибута добавляется слово DESC .
Выдать список оценок, которые получил студент с кодом "1" .
Выдать список кодов студентов, которые получили на экзаменах хотя бы одну двойку или тройку .
В предложении WHERE можно записывать выражение с использованием арифметических операторов сравнения (<, >, и т.д.) и логических операторов (AND, OR, NOT ) как и в обычных языках программирования.
Наряду с операторами сравнения и логическими операторами для составления условий в языке SQL (из-за специфики области применения) существуют ряд специальных операторов, которые, как правило, не имеют аналогов в других языках. Вот эти операторы :
- IN – вхождение в некоторое множество значений;
- BETWEEN – вхождение в некоторый диапазон значений;
- LIKE – проверка на совпадение с образцом;
- IS NULL – проверка на неопределенное значение.
Оператор IN используется для проверки вхождения в некоторое множество значений. Так, запрос
дает тот же результат, что и вышеуказанный запрос (выведет идентификаторы всех абитуриентов, получивших хотя бы одну двойку или тройку на экзаменах).
Того же результата можно добиться, используя оператор BETWEEN :
Выдать список всех студентов, фамилии которых начинаются с буквы А .
В этом случае удобно использовать оператор LIKE .
Оператор LIKE применим исключительно к символьным полям и позволяет устанавливать, соответствует ли значение поля образцу. Образец может содержать специальные символы:
_ (символ подчеркивания) – замещает любой одиночный символ;
% (знак процента) – замещает последовательность любого числа символов.
Очень часто возникает необходимость произвести вычисление минимальных, максимальных или средних значений в столбцах. Так, например, может понадобиться вычислить средний балл. Для осуществления подобных вычислений SQL предоставляет специальные агрегатные функции :
- MIN – минимальное значение в столбце;
- MAX – максимальное значение в столбце;
- SUM – сумма значений в столбце;
- AVG – среднее значение в столбце;
- COUNT – количество значений в столбце, отличных от NULL.
Следующий запрос считает среднее среди всех баллов, полученных студентами на экзаменах.
SELECT AVG(mark) FROM mark_st
Естественно, можно использовать агрегатные функции совместно с предложением WHERE :
Данный запрос вычислит средний балл студента с кодом 100 по результатам всех сданных им экзаменов.
Данный запрос вычислит средний балл студентов по результатам сдачи экзамена с кодом 10.В дополнение к рассмотренным механизмам
Основу языка SQL составляют операторы, условно разбитые не несколько групп по выполняемым функциям.
Можно выделить следующие группы операторов (перечислены не все операторы SQL):
Операторы DDL (Data Definition Language) - операторы определения объектов базы данных
· CREATE SCHEMA - создать схему базы данных
· DROP SHEMA - удалить схему базы данных
· CREATE TABLE - создать таблицу
· ALTER TABLE - изменить таблицу
· DROP TABLE - удалить таблицу
· CREATE DOMAIN - создать домен
· ALTER DOMAIN - изменить домен
· DROP DOMAIN - удалить домен
· CREATE COLLATION - создать последовательность
· DROP COLLATION - удалить последовательность
· CREATE VIEW - создать представление
· DROP VIEW - удалить представление
Операторы DML (Data Manipulation Language) - операторы манипулирования данными
· SELECT - отобрать строки из таблиц
· INSERT - добавить строки в таблицу
· UPDATE - изменить строки в таблице
· DELETE - удалить строки в таблице
· COMMIT - зафиксировать внесенные изменения
· ROLLBACK - откатить внесенные изменения
Операторы защиты и управления данными
· CREATE ASSERTION - создать ограничение
· DROP ASSERTION - удалить ограничение
· GRANT - предоставить привилегии пользователю или приложению на манипулирование объектами
· REVOKE - отменить привилегии пользователя или приложения
Кроме того, есть группы операторов установки параметров сеанса, получения информации о базе данных, операторы статического SQL, операторы динамического SQL.
Наиболее важными для пользователя являются операторы манипулирования данными (DML).
Примеры использования операторов манипулирования данными
INSERT - вставка строк в таблицу
Пример 1 . Вставка одной строки в таблицу:
VALUES (4, "Иванов");
UPDATE - обновление строк в таблице
Пример 3 . Обновление нескольких строк в таблице:
SET PNAME = "Пушников"
WHERE P.PNUM = 1;
DELETE - удаление строк в таблице
Пример 4 . Удаление нескольких строк в таблице:
WHERE P.PNUM = 1;
Примеры использования оператора SELECT
Оператор SELECT является фактически самым важным для пользователя и самым сложным оператором SQL. Он предназначен для выборки данных из таблиц, т.е. он, собственно, и реализует одно их основных назначение базы данных - предоставлять информацию пользователю.
Оператор SELECT всегда выполняется над некоторыми таблицами, входящими в базу данных.
Замечание . На самом деле в базах данных могут быть не только постоянно хранимые таблицы, а также временные таблицы и так называемые представления. Представления - это просто хранящиеся в базе данные SELECT-выражения. С точки зрения пользователей представления - это таблица, которая не хранится постоянно в базе данных, а "возникает" в момент обращения к ней. С точки зрения оператора SELECT и постоянно хранимые таблицы, и временные таблицы и представления выглядят совершенно одинаково. Конечно, при реальном выполнении оператора SELECT системой учитываются различия между хранимыми таблицами и представлениями, но эти различия скрыты от пользователя.
Результатом выполнения оператора SELECT всегда является таблица. Таким образом, по результатам действий оператор SELECT похож на операторы реляционной алгебры. Любой оператор реляционной алгебры может быть выражен подходящим образом сформулированным оператором SELECT. Сложность оператора SELECT определяется тем, что он содержит в себе все возможности реляционной алгебры, а также дополнительные возможности, которых в реляционной алгебре нет.
Порядок выполнения оператора SELECT
Для того чтобы понять, как получается результат выполнения оператора SELECT, рассмотрим концептуальную схему его выполнения. Эта схема является именно концептуальной, т.к. гарантируется, что результат будет таким, как если бы он выполнялся шаг за шагом в соответствии с этой схемой. На самом деле, реально результат получается более изощренными алгоритмами, которыми "владеет" конкретная СУБД.
Стадия 1. Выполнение одиночного оператора SELECT
Если в операторе присутствуют ключевые слова UNION, EXCEPT и INTERSECT, то запрос разбивается на несколько независимых запросов, каждый из которых выполняется отдельно:
Шаг 1 (FROM) . Вычисляется прямое декартовое произведение всех таблиц, указанных в обязательном разделе FROM. В результате шага 1 получаем таблицу A.
Шаг 2 (WHERE) . Если в операторе SELECT присутствует раздел WHERE, то сканируется таблица A, полученная при выполнении шага 1. При этом для каждой строки из таблицы A вычисляется условное выражение, приведенное в разделе WHERE. Только те строки, для которых условное выражение возвращает значение TRUE, включаются в результат. Если раздел WHERE опущен, то сразу переходим к шагу 3. Если в условном выражении участвуют вложенные подзапросы, то они вычисляются в соответствии с данной концептуальной схемой. В результате шага 2 получаем таблицу B.
Шаг 3 (GROUP BY) . Если в операторе SELECT присутствует раздел GROUP BY, то строки таблицы B, полученной на втором шаге, группируются в соответствии со списком группировки, приведенным в разделе GROUP BY. Если раздел GROUP BY опущен, то сразу переходим к шагу 4. В результате шага 3 получаем таблицу С.
Шаг 4 (HAVING) . Если в операторе SELECT присутствует раздел HAVING, то группы, не удовлетворяющие условному выражению, приведенному в разделе HAVING, исключаются. Если раздел HAVING опущен, то сразу переходим к шагу 5. В результате шага 4 получаем таблицу D.
Шаг 5 (SELECT) . Каждая группа, полученная на шаге 4, генерирует одну строку результата следующим образом. Вычисляются все скалярные выражения, указанные в разделе SELECT. По правилам использования раздела GROUP BY, такие скалярные выражения должны быть одинаковыми для всех строк внутри каждой группы. Для каждой группы вычисляются значения агрегатных функций, приведенных в разделе SELECT. Если раздел GROUP BY отсутствовал, но в разделе SELECT есть агрегатные функции, то считается, что имеется всего одна группа. Если нет ни раздела GROUP BY, ни агрегатных функций, то считается, что имеется столько групп, сколько строк отобрано к данному моменту. В результате шага 5 получаем таблицу E, содержащую столько колонок, сколько элементов приведено в разделе SELECT и столько строк, сколько отобрано групп.
Стадия 2. Выполнение операций UNION, EXCEPT, INTERSECT
Если в операторе SELECT присутствовали ключевые слова UNION, EXCEPT и INTERSECT, то таблицы, полученные в результате выполнения 1-й стадии, объединяются, вычитаются или пересекаются.
Стадия 3. Упорядочение результата
Если в операторе SELECT присутствует раздел ORDER BY, то строки полученной на предыдущих шагах таблицы упорядочиваются в соответствии со списком упорядочения, приведенном в разделе ORDER BY.
Вопрос №1. SQL и его история. 1
Вопрос №2. Описание основных операторов SQL.. 1
Арифметические функции. 4
Функции обработки строк. 5
Специальные функции. 6
Функции для обработки даты.. 7
Использование агрегатных функций в запросах. 7
Вопрос №1. SQL и его история
Единственным средством общения и администраторов баз данных, и проектировщиков, и разработчиков, и пользователей с реляционной базой данных является структурированный язык запрос SQL (Structured Query Language). SQL есть полнофункциональный язык манипулирования данными в реляционных базах данных. В настоящее время он является общепризнанным, стандартным интерфейсом для реляционных баз данных, таких как Oracle, Informix, Sybase, DB/2, MS SQL Server и ряда других (стандарты ANSI и ISO). SQL - непроцедурный язык, который предназначен для обработки множеств, состоящих из строк и колонок таблиц реляционной базы данных. Хотя существуют его расширения, допускающие процедурную обработку. Проектировщики баз данных используют SQL для создания всех физических объектов реляционной базы данных.
Теоретические основы SQL были заложены в известной статье Кодда, положившей начало развитию теории реляционных БД. Первая практическая реализации была выполнена в исследовательских лабораториях фирмы IBM Chamberlin D.D. и Royce R.F. Промышленное применение SQL было впервые реализовано в СУБД Ingres. Одной из первых промышленных реляционных СУБД является Oracle. По сути дела, реляционная СУБД - это программное обеспечение, которое управляет работой реляционной базы данных.
Первый международный стандарт языка SQL был принят в 1989 г. (SQL-89). В конце 1992 г. был принят новый международный стандарт SQL-92. В настоящее время большинство производителей реляционных СУБД используют его в качестве базового. Однако работы по стандартизации языка SQL далеки от завершения и уже разработан проект стандарта SQL-99, который вводит в обиход языка понятие объекта и разрешает на него ссылаться в операторах SQL: В исходном варианте SQL не было команд управления потоком данных, они появились в недавно принятом стандарте ISO/IEC 9075-5: 1996 дополнительной части SQL.
Каждой конкретной СУБД соответствует своя собственная реализация SQL, в целом поддерживающая определенный стандарт, но имеющая свои особенности. Эти реализации называются диалектами. Так, стандарт 1SO/IEC 9075-5 предусматривает объекты, называемые постоянно хранимыми модулями или PSM-модулями (Persistent Stored Modules). В СУБД Oracle расширение PL/SQL является аналогом указанного выше расширения стандарта".
Вопрос №2. Описание основных операторов SQL
SQL состоит из набора команд манипулирования данными в реляционной базе данных, которые позволяют создавать объекты реляционной базы данных, модифицировать данные в таблицах (вставлять, удалять, исправлять), изменять схемы отношений базы данных, выполнять вычисления над данными, делать выборки из базы данных, поддерживать безопасность и целостность данных.
Весь набор команд SQL можно разбить на следующие группы:
· команды определения данных (DDL - Data Defininion Language);
· команды манипулирования данными (DML - Data Manipulation Language);
· команды выборки данных (DQL - Data Query Language);
· команды управления транзакциями;
· команды управления данными.
При выполнении каждая команда SQL проходит четыре фазы обработки:
· фаза синтаксического разбора, которая включает проверку синтаксиса команды, проверку имен таблиц и колонок в базе данных, а также подготовку исходных данных для оптимизатора;
· фаза оптимизации, которая включает подстановку действительных имен таблиц и колонок базы данных в представление, идентификацию возможных вариантов выполнения команды, определение стоимости выполнения каждого варианта, выбор наилучшего варианта на основе внутренней статистики;
· фаза генерации исполняемого кода, которая включает построение выполняемого кода команды;
· фаза выполнения команды, которая включает выполнение кода команды.
В настоящее время оптимизатор является составной частью любой промышленной реализации SQL. Работа оптимизатора основана на сборе статистики о выполняемых командах и выполнении эквивалентных алгебраических преобразований с отношениями базы данных. Такая статистика сохраняется в системном каталоге базы данных. Системный каталог является словарем данных для каждой базы данных и содержит информацию о таблицах, представлениях, индексах, колонках, пользователях и их привилегиях доступа. Каждая база данных имеет свой системный каталог, который представляет совокупность предопределенных таблиц базы данных.
Таблица 8.1 содержит список команд SQL в соответствии с принятым стандартом, за исключением некоторых практически не используемых в диалектах команд.
Таблица 8.1. Типичный список команд SQL
| Команда | Описание |
| Команды определения данных объектов | |
| ALTER TABLE | Изменяет описание таблицы (схему отношения) |
| CREATE EVENT | Создает событие таймера в базе данных |
| CREATE INDEX | Создаст индекс для таблицы |
| CREATE SEQUENCE | Создает последовательность |
| CREATE TABLE | Определяет таблицу |
| CREATE TABLESPACE | Создаст табличное пространство |
| CREATE TRIGGER | Создает триггер в базе данных |
| CREATE VIEW | Определяет представление на таблицах |
| DROP INDEX | Физически удаляет индекс из базы данных |
| DROP SEQUENCE | Удаляет последовательность |
| DROP TABLE | Физически удаляет таблицу из базы данных |
| DROP TABLESPACE | Удаляет табличное пространство |
| DROP VIEW | Удаляет представление |
| Команды манипулирования данными | |
| DELETE | Удаляет одну или более строк из таблицы базы данных |
| INSERT | Вставляет одну или более строк в таблицу базы данных |
| UPDATE | Обновляет значения колонок в таблице базы данных |
| Команды выборки данных | |
| SELECT | Выполняет запрос на выборку данных из таблиц и представлений |
| UNION | Объединяет в одной выборке результаты выполнения двух или более команд SELECT |
| Команды управления транзакциями | |
| COMMIT | Завершает транзакцию и физически актуализирует текущее состояние базы данных |
| ROLLBACK | Завершает транзакцию и возвращает текущее состояние базы данных на момент последней завершенной транзакции и контрольной точки |
| SAVEPOINT | Назначает контрольную точку внутри транзакции |
| Команды управления данными | |
| ALTER DATABASE | Изменяет группы хранения или журналы транзакций |
| ALTER DBAREA | Изменяет размер областей хранения базы данных |
| ALTER PASSWORD | Изменяет пароль для доступа к базе данных |
| ALTER STOGROUP | Изменяет состав областей хранения в группе хранения |
| CHECK DATABASE | Проверяет целостность базы данных |
| CHECK INDEX | Проверяет целостность индекса |
| CHECK TABLE | Проверяет целостность таблицы и индекса |
| CREATE DATABASE | Физически создает базу данных |
| CREATE DBAREA | Создает область хранения базы данных |
| CREATE STOGROUP | Создает группу хранения |
| CREATE SYSNONYM | Создает синоним для таблицы или представления |
| DEINSTALL DATABASE | Делает базу данных недоступной пользователям вычислительной сети |
| DROP DATABASE | Физически удаляет базы данных |
| DROP DBAREA | Физически удаляет область хранения базы данных |
| DROP STOGROUP | Удаляет группу хранения |
| GRANT | Определяет привилегии пользователей и разграничение доступа к базе данных |
| INSTALL DATABASE | Делает базу данных доступной пользователям вычислительной сети |
| LOCK DATABASE | Блокирует текущую активную базу данных |
| REVOKE | Отменяет привилегии пользователей и разграничения доступа к базе данных |
| SET DEFAULT STOGROUP | Определяет группу хранения по умолчанию |
| UNLOCK DATABASE | Деблокирует текущую активную базу данных |
| UPDATE STATISTIC | Обновляет статистику для базы данных |
| Другие команды | |
| COMMENT ON | Размещает в системном каталоге комментарии к описанию объектов БД |
| CREATE SYNONYM | Определяет в системном каталоге альтернативные имена для таблиц и представлений БД |
| DROP SYNONYM | Удаляет из системного каталога альтернативные имена для таблиц и представлений БД |
| LABEL | Изменяет метки системных описаний |
| ROWCOUNT | Вычисляет число строк в таблице БД |
Набор команд SQL, перечисленный в таблице, не является полным. Этот список приведен, чтобы вы составили впечатление о возможностях SQL в целом. Для получения полного списка команд следует обратиться к соответствующему руководству для конкретной СУБД. Следует помнить, что SQL является единственным средством общения всех категорий пользователей с реляционными базами данных.
Арифметические функции
SQL поддерживает полный набор арифметических операций и математических функций для построения арифметических выражений над колонками базы данных (+, -, *, /, ABS, LN, SQRT и т.д.).
Список основных встроенных математических функций дан ниже в таблице 8.2.
| Математическая функция | Описание |
| ABS(X) | Возвращает абсолютное значение числа X |
| ACOS(X) | Возвращает арккосинус числа X |
| ASIN(X) | Возвращает арксинус числа X |
| ATAN(X) | Возвращает арктангенс числа X |
| COS(X) | Возвращает косинус числа X |
| EXP(X) | Возвращает экспоненту числа X |
| SIGN(X) | Возвращает -], если X < 0, 0, если X = 0, + 1, если X > 0 |
| LN(X) | Возвращает натуральный логарифм числа X |
| MOD(X,Y) | Возвращает остаток от деления X на Y |
| CEIL(X) | Возвращает наименьшее целое, большее или равное X |
| ROUND(X,n) | Округляет число X до числа с п знаками после десятичной точки |
| SIN(X) | Возвращает синус числа X |
| SQRT(X) | Возвращает квадратный корень числа X |
| TAN(X) | Возвращает тангенс числа X |
| FLOOR(X) | Возвращает наибольшее целое, меньшее или равное X |
| LOG(a,X) | Возвращает логарифм числа X по основанию А |
| SINH(X) | Возвращает гиперболический синус числа X |
| COSH(X) | Возвращает гиперболический косинус числа X |
| TANH(X) | Возвращает гиперболический тангенс числа X |
| TRANC(X.n) | Усекает число X до числа с п знаками после десятичной точки |
| POWER(A,X) | Возвращает значение А, возведенное в степень X |
Набор встроенных функций может изменяться в зависимости от версии СУБД одного производителя и также в СУБД различных производителей. Так, например, в СУБД SQLBase, Centure Inc. есть функция @ATAN2(X,Y), которая возвращает арктангенс Y/X, но отсутствует функция SIGN(X).
Арифметические выражения необходимы для получения данных, которые непосредственно не сохраняются в колонках таблиц базы данных, но значения которых необходимы пользователю. Допустим, что вам необходим список служащих, показывающий выплату, которую получил каждый служащий с учетом премий и штрафов.
SELECT ENAME, SAL, COMM. FINE, SAL + COMM - FINE
Арифметическое выражение SAL + COMM - FINE выводится как новая колонка в результирующей таблице, которая вычисляется в результате выполнения запроса. Такие колонки называют еще производными (вычисляемыми) атрибутами или полями.
Функции обработки строк
SQL предоставляет вам широкий набор функций для манипулирования со строковыми данными (конкатенация строк, CHR, LENGTH, INSTR и другие). Список основных функций для обработки строковых данных приведен в таблице 8.3.
Таблица 8.3. Функции SQL для обработки строк
| Функция | Описание |
| CHR(N) | Возвращает символ ASCII кода для десятичного кода N |
| ASCII(S) | Возвращает десятичный ASCII код первого символа строки |
| INSTR(S2,SI,pos|,N|) | Возвращает позицию строки SI в строке S2 большую или равную pos. N - число вхождений |
| LENGTH(S) | Возвращает длину строки |
| LOWER(S) | Заменяет все символы строки на прописные символы |
| INITCAP(S) | Устанавливает первый символ каждого слова в строке на заглавный, а остальные символы каждого слова - на прописные |
| SUBSTR(S,pos,[,len|) | Выделяет в строке S подстроку длиной ten, начиная с позиции pos |
| UPPER(S) | Преобразует прописные буквы в строке на заглавные буквы |
| LPAD(S,N |,A|) | Возвращает строку S, дополненную слева символами А до числа символов N. Символ-наполнитель по умолчанию - пробел |
| RPAD(S,N |,А]) | Возвращает строку S, дополненную справа символами А до числа символов N. Символ-наполнитель по умолчанию - пробел |
| LTRIM(S,|,Sll) | Возвращает усеченную слева строку S. Символы удаляются до тех пор, пока удаляемый символ входит в строку - шаблон SI (по умолчанию - пробел) |
| RTRIM(S,|,SI |) | Возвращает усеченную справа строку S. Символы удаляются до тех пор, пока удаляемый символ входит в строку - шаблон S1 (по умолчанию - пробел) |
| TRANSLATES,(SI,S2) | Возвращает строку S, в которой все вхождения строки SI замещены строкой S2. Если SI <>S2, то символы, которым нет соответствия, исключаются из результирующей строки |
| REPLACED(SI,|,S2|) | Возвращает строку S, для которой все вхождения подстроки SI замещены на подстроку S2. Если S2 не указано, то все вхождения подстроки SI удаляются из результирующей строки S |
| NVL(X,Y) | Если X есть NULL, то возвращает в Y либо строку, либо число, либо дату в зависимости от исходного типа Y |
Названия одних и тex же функций могут отличаться в различных СУБД. Так, например, функция СУБД Oracle SUBSTR(S, pos, |, len|) в СУБД SQLBase называется @SUBSTRING(S, pos, Ien). В СУБД SQLBase имеются функции, которых нет в СУБД Oracle (см. таблицу ниже, где приведен список таких функций).
Таблица 8.4. Строковые функции СУБД SQLBase, отличающиеся от строковых функций СУБД Oracle
| Функция | Описание |
| @EXACT(SI,S2) | Возвращает результат сравнения двух строк |
| @LEFT(S,lcn) | Возвращает левую подстроку длиной len |
| @LENGTH(S) | Возвращает дли ну строки |
| @MID(S, pos, len) | Возвращает подстроку указанной длины, начиная с позиции pos |
| @REPEAT(S,n) | Повторяет строку S n раз |
| @REPLACE(SI,pos,len,S2) | Замещаете позиции pos len символов в строке S2 символами строки SI |
| @RIGHT(S,len) | Возвращает правую подстроку S длиной len |
| @SCAN(S,pat) | Возвращает позицию подстроки pat в строке S |
| @STRING(X, scale) | Возвращает символьное представление числа с указанным масштабом scale |
| @TRIM(S) | Удаляет пробелы в строке справа и слева |
| @VALUE(S) | Преобразует символьное представление числа в числовое значение |
Можно использовать функцию INITCAP, чтобы при получении списка имен служащих фамилии всегда начинались с заглавной буквы, а все остальные были прописными.
SELECT INITCAP(ENAME)
Специальные функции
SQL обеспечивает набор специальных функций для преобразований значений колонок. Список таких функций приведен в таблице 8.5.
Таблица 8.5. Специальные функции
В таблице EMPLOYEE для каждого служащего можно ввести признак пола - добавить колонку SEX типа CHAR(l) (0 - мужской, 1 - женский). Допустим, что вам нужен список служащих, в котором требуется разделение их по признаку пола с указанием его в числовом формате; тогда можно задать такую команду:
SELECT ENAME, LNAME, AGE, "Пол :", TO_NUMBER(SEX)
В качестве примера использования функцииDECODE приведем запрос, вычисляющий список служащих с указанием их руководителя. Если руководитель неизвестен, то выводится по умолчанию «не имеет».
SELECT ENAME, DEC0DE(DEPN0, 10, "Дрягин" , 20,"Жиляева ". 30,"
Коротков ", "не имеет" )
Предположим, что руководитель организации имеет неопределенное значение колонкиDEPNO и, следовательно, для него будет работать умолчание, предусмотренное вDECODE.
©2015-2019 сайт
Все права принадлежать их авторам. Данный сайт не претендует на авторства, а предоставляет бесплатное использование.
Дата создания страницы: 2016-08-07
И над данными таблиц.
Язык SQL называют встроенным , т.к. он содержит функций полноценного языка разработки, а ориентируется на доступ к данным, вследствие чего он входит в состав средств разработки приложений. Стандарты языка SQL поддерживают языки программирования Pascal, Fortran, COBOL, С и др.
Существует 2 метода использования встроенного SQL :
- статическое использование языка (статический SQL ) – в тексте программы содержатся вызовы функций SQL, которые включают в исполняемый модуль после компиляции.
- динамическое использование языка (динамический SQL ) – динамическое построение вызовов функций SQL и их интерпретация. Например , можно обратиться к данным удаленной БД в процессе выполнения программы.
Язык SQL (как и другие языки для работы с БД) предназначен для подготовки и выполнения запросов. В результате выполнения запроса данных из одной или нескольких таблиц получают множество записей, которое называют представлением .
Определение 1
Представление – это таблица, которая формируется в результате выполнения запроса.
Основные операторы языка запросов SQL
Операторы языка SQL условно разделяются на 2 подъязыка :
- Язык определения данных DDL ;
- Язык манипулирования данными DML .
В таблице символом * помечены специфические операторы языка.
Рассмотрим важнейшие операторы SQL.
Оператор создания таблицы:
Имя таблицы, которая создается, и имя хотя бы одного столбца (поля) являются обязательными операндами. Для имени столбца необходимо указать тип данных, которые будут в нем храниться.
Для отдельных полей можно указывать дополнительные правила контроля значений, которые в них вводятся. Например, NOT NULL обозначает, что поле не может быть пустым и в него должно быть введено значение.
Пример 1
Для создания таблицы books каталога книг, которая содержит поля:
type – тип книги,
name – название книги,
price – цена книги
оператор может выглядеть следующим образом:
Оператор изменения структуры таблицы:
При изменении структуры таблицы можно добавлять (ADD ), изменять (MODIFY ) или удалять (DROP ) один или несколько столбцов таблицы. Правила записи данного оператора такие же, как и для оператора CREATE TABLE . Чтобы удалить столбец указывать не нужно.
Пример 2
Для добавления к таблице books поля number , в котором будет храниться количество книг, можно записать оператор:
Оператор удаления таблицы:
Пример 3
Например, чтобы удалить существующую таблицу с именем books достаточно воспользоваться оператором:
Оператор создания индекса:
Оператор создает индекс для одного или нескольких столбцов данной таблицы, который позволяет ускорить выполнение операций запроса и поиска. Для одной таблицы может быть создано несколько индексов.
Необязательная опция UNIQUE отвечает за обеспечение уникальности значений во всех столбцах, которые указаны в операторе.
ASC задает автоматическую сортировку значений в столбцах в порядке возрастания (по умолчанию), а DESC – в порядке убывания.
Оператор удаления индекса:
Оператор создания представления:
При создании представления можно не указывать имена столбцов. Тогда будут использованы имена столбцов из запроса, который описывается соответствующим оператором SELECT .
Оператор удаления представления:
Оператор выборки записей:
Оператор SELECT производит выборку и вычисления над данными из одной или нескольких таблиц. Результат выполнения оператора – ответная таблица, которая содержит (ALL ) или не содержит (DISTINCT ) строки, которые повторяются.
Операнд FROM содержит список таблиц, из которых берутся записи для отбора данных.
Оператор изменения записей:
Новые значения полей в записях могут не содержать значений (NULL ) или вычисляться согласно арифметическому выражению.
Оператор вставки новых записей:
В первой записи оператора INSERT вводятся новые записи с заданными значениями в столбцах.
Во втором записи оператора INSERT вводятся новые строки, отобранные из другой таблицы через предложение SELECT .
Оператор удаления записей:
В результате выполнения оператора удаляются из указанной таблицы строки, удовлетворяющие условию, которое определено необязательным операндом WHERE . Если операнд WHERE не указан, то удаляются все записи таблицы.